솔브드는 문제해결을 좀 더 재밌게 할 수 있도록 항상 여러 고민들을 하고 있습니다. 항상 솔브드의 기획을 도와 주시는 havana723님의 아이디어로 이번에는 (문제해결 자체와는 약간 거리가 있지만) 시즌 2 종료를 기념으로 지금까지의 성과를 모아볼 수 있는 개인화 굿즈를 만들었습니다. 시즌 2 종료 시점의 프로필과 1년간의 변화량, 그리고 스트릭이 있는 아크릴 굿즈 등입니다. 지난 1년을 돌아보고 다음 1년의 의지를 다지는 계기가 되길 바라는 마음으로 준비했습니다.
이번 굿즈 샵의 총 주문 건은 정확한 값을 밝힐 수는 없지만 몇 백에서 천몇 백 건 쯤이었습니다. 이렇게 많은 개인화 작업을 어떻게 했는지 시행착오와 우여곡절을 이야기해 보려고 합니다.

시제품
아크릴 굿즈의 제작은 디자인으로부터 시작됩니다.
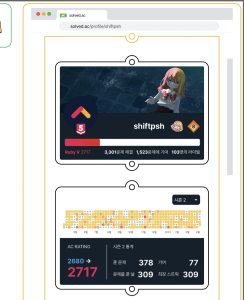
디자인은 굿즈 제작에서 제일 쉬운 부분입니다. 다만 고려해야 할 점들이 있습니다. 바로 인쇄가 되는 방식인데요, 인쇄 방식이 다소 특이해서 인쇄소에 세 개의 파일을 제출해야 합니다.
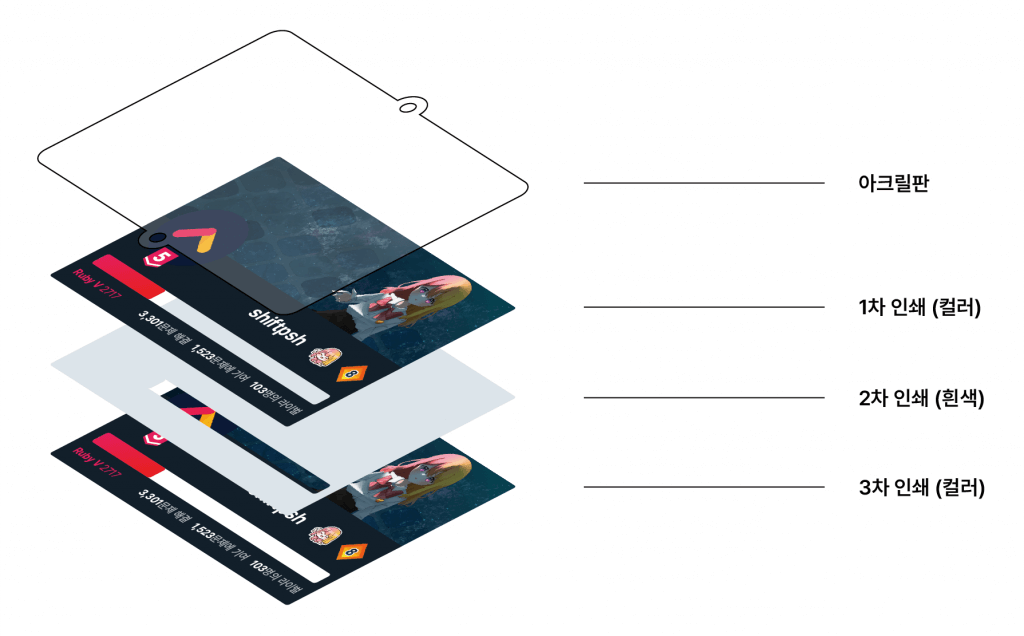
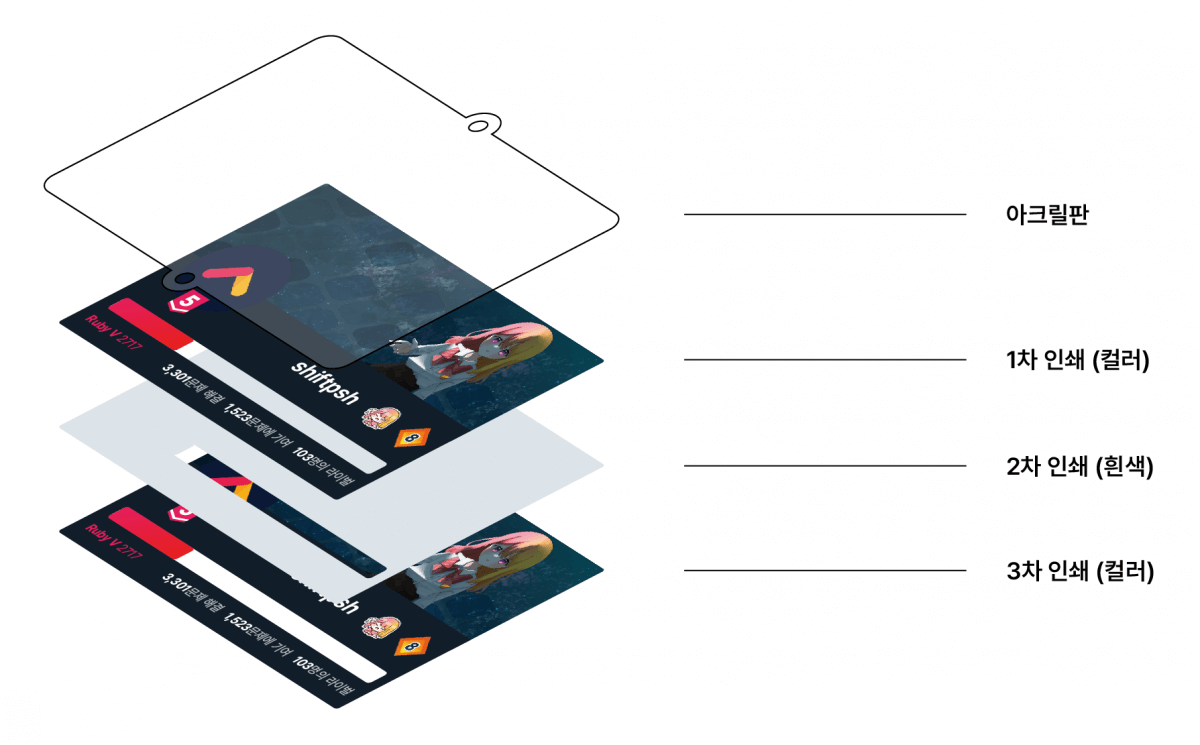
아크릴은 기본적으로 투명한 재료입니다. 투명한 매체에 한 번만 인쇄하면 글씨도 투명해지기 때문에, 보통 위 그림과 같이 색상을 1차로 인쇄하고, 거기에 흰색 잉크로만 2차로 인쇄해 발색이 선명하도록 합니다. 뒷면이 흰색이면 예쁘지 않기 때문에 색상을 3차로 한 번 더 인쇄해 앞뒷면이 같도록 할 수 있습니다. 앞면에 인쇄된 내용의 손상을 막기 위해 앞면이 아니라 뒷면에 차곡차곡 인쇄됩니다.
따라서 디자인은 하나를 하더라도 인쇄소에 보낼 파일은 총 세 개가 됩니다. 아크릴 모양을 결정하는 칼선 파일, 인쇄할 내용을 결정하는 색상 파일, 그리고 인쇄 영역 중 발색을 선명하게 할 부분을 결정하는 흰색 파일입니다. 또, 뒷면에 인쇄하기 때문에 파일은 전부 좌우반전되어 있어야 합니다.
일반적인 아크릴 굿즈 작업파일은 아래와 같이 됩니다.
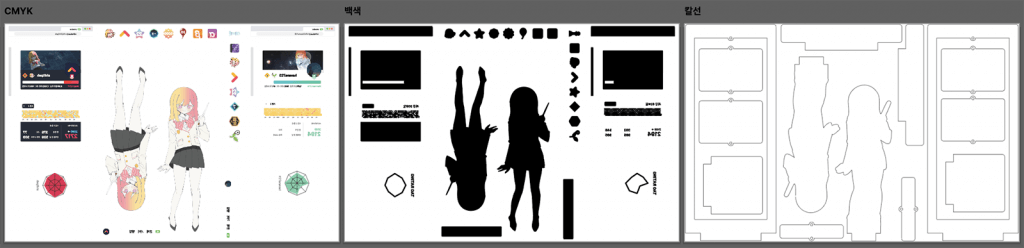
인쇄물이기 때문에 색상 작업은 CMYK로 해야 하는데요, CMYK는 잉크의 비율로 색상을 나타내는 방법이기 때문에 따로 ‘투명도’라는 개념이 없고, 따라서 투명과 흰색이 구별되지 않습니다. 그런 이유로 흰색 파일에서 흰색으로 인쇄할 영역은 대신 검정 잉크 100%로 작업해야 합니다.

그리고 보통 제가 사용하는 글꼴이 인쇄업체에 설치되어 있지 않은 경우도 일반적이기 때문에 모든 글자를 도형으로 바꿔서 파일로 전달해야 합니다.
여기까지가 이제 제가 일상적으로 하는 일입니다. 디자인을 시작한 시점부터 여기까지 오는 데에는 하루면 충분합니다. 다만 이건 한 종류의 디자인을 할 때의 이야기입니다.
많은 종류의 디자인을 작업해야 한다면
하지만 몇십 몇백 종류의 디자인을 작업해야 한다면 이야기는 조금 달라집니다. 이번 굿즈 샵의 경우가 딱 그렇습니다. 주문자의 1년 통계를 불러와서 디자인에 적용해야 합니다.
디자인 프로그램은 그렇게 친절하지 않습니다. 값을 하나하나 바꾸고, 글자들을 도형으로 바꾸고, 좌우반전하는 과정을 거쳐야 합니다. 이 과정에서 실수를 하지 않기란 어렵습니다.
하지만 우리가 누군가요, 개발자잖아요! 아마도 이런 작업을 자동화할 수 있는 좋은 방법이 있을 겁니다.
첫 번째 방법 — ExtendScript (실패)
제가 아크릴 파일을 제작하는 프로그램인 Adobe Illustrator에도 이런 자동화에 대한 수요가 많기 때문에 ‘액션’이라는 기능을 제공합니다. 일련의 작업 과정을 ‘녹화’하고, 나중에 액션을 한 번 클릭하면 녹화한 작업 과정을 그대로 실행해 줍니다. 말 그대로 매크로 같은 기능입니다.

그리고 더 나아가서 ExtendScript라는 자체 스크립팅 언어로 매크로를 짤 수도 있습니다. 예전에는 ExtendScript Toolkit이라는 자체 IDE를 제공했지만, 요즘은 VS Code 확장 플러그인을 설치해서 VS Code에서 ExtendScript 코드를 작성할 수 있습니다.
말이 ExtendScript지 사실 JavaScript와 거의 유사한 언어라서, TypeScript로 밥을 벌어먹고 있는 제가 쓰기에는 최고라고 생각했습니다. 이 기능이 있다는 걸 생각해내자마자 이 스크립트로 굿즈 파일을 자동 생성해 보기로 결심하고, 리서치에 들어갔습니다. ExtendScript가 JavaScript ES3 기반이라는 걸 알기 전까지는 순탄해 보였습니다.
저는 TypeScript 없는 환경에서 작업하지 않기 때문에 어떻게든 모던한 개발 방식으로 코드를 작성하고, 하나의 매크로 파일로 묶어 보려고 환경을 구성을 시도했습니다. Webpack과 TypeScript를 쓸 수 있으면 좋을 것 같습니다.
타입 정의와 API 문서
타입 정의는 따로 Adobe에서 제공하는 것은 없고, 대신 types-for-adobe라는 패키지가 있습니다. 문서도 docsforadobe.dev에 올라와 있는데, 공식인지 아닌지는 잘 모르겠습니다.
Typescript: "target": "es3"
놀랍게도 tsconfig.json의 target 필드의 값으로 es3이 허용됩니다1, 2. TypeScript 컴파일러 tsc는 아래와 같은 코드를…
`Hello ${person}, today is ${date.toDateString()}!`;
… 이렇게 바꿔 줍니다.
"Hello ".concat(person, ", today is ").concat(date.toDateString(), "!");
와, 즐겁네요! 이제 ES6 기능을 마구마구 쓰면서 개발할 수 있겠습니다.
아래 코드가 실행되지 않는 걸 경험하기 전까지는 말이죠.
elements.forEach((e) => e.move(groupItem, ElementPlacement.PLACEATBEGINNING));
로그를 열어 보니 forEach가 없다고 합니다. 아니, downleveling 잘 해 준다며요!
애석하게도 forEach라던가 Map, Set 같은 것들은 polyfill되지 않습니다. 이런 것들은 직접 polyfill해 줘야 합니다.
core-js
좋아요, polyfill이라는 단어가 나왔으니 core-js를 써 봅시다. webpack.config.js를 만들고, @babel/preset-env 같은 걸 구성해 봅시다.
그러면 이제 아래 코드가 실행이 안 됩니다.
x >= 10 ? x.toString() : x < 0 ? '00' : `0${x}`
이건 또 왜일까요?

ES3 스펙은 삼항 연산자 안에 삼항 연산자를 쓸 수 있도록 되어 있습니다3. 여기서 하나 상기해야 되는 사실이 있습니다. 이 코드가 돌아가는 환경은 어떤 Node 런타임과도, 어떤 브라우저와도 다르다는 사실입니다.
안타깝게도 ExtendScript는 ES3 같은 무언가지 ES3 그 자체가 아닙니다. Adobe가 ES3을 구현하려고 노력한 결과물입니다. 구현에 성공한 결과물이 아닙니다.
그런 이유로, ExtendScript에서 삼항 연산자 안에 삼항 연산자를 바로 적는 것은 허용되지 않습니다. 괄호를 씌워줘야 합니다(a ? (b ? c : d) : e)4.
ESLint 입장에서는 이런 환경은 듣도 보도 못했으므로 당연히 빨간 줄도 안 그어 줍니다. 빨간 줄을 그어 주기 위해 babel 플러그인을 만들어야 했습니다.
module.exports = function (babel) {
const { types: t } = babel;
return {
name: "wrap-ternary-in-parentheses",
visitor: {
ConditionalExpression(path) {
const { node } = path;
// Only transform if not already in parentheses
if (!t.isParenthesizedExpression(path.parent)) {
const parenthesizedExpression = t.parenthesizedExpression(node);
path.replaceWith(parenthesizedExpression);
}
},
},
};
};
유감스럽게도 이와 같은 코드를 몇 개 더 짜야 했습니다.
산 넘어 산
일단 어떻게든 샘플 데이터로 태그 레이팅 아크릴을 그리는 데에 성공했습니다. 이제 자동화를 해야겠죠? 일단 ExtendScript로 전부 해 보려고 했습니다.
여기서 ExtendScript와 일반적인 자바스크립트 환경이 갖는 또 다른 차이점이 발목을 잡습니다. ExtendScript에는 fetch가 없습니다. 이 정도는 예상했으니까 그럴 수 있다고 칩시다. 그런데 XMLHttpRequest도 없습니다. ExtendScript가 네트워크와 통신할 수 있는 유일한 방법은 소켓을 직접 여는 것뿐입니다.

system.callSystem()이라는 게 있긴 한데, 이건 Illustrator에는 없고 Bridge라는 다른 앱에만 있는 기능이라, BridgeTalk 같은 걸 써야 했습니다. 이걸로 curl 해서 가져올 수 있는가 싶었는데, 결과적으로 잘 안 됐습니다.
자동화를 솔브드의 관리자 API를 직접 호출하는 방법으로 하려고 했는데, 이래서는 TCP 소켓을 기반으로 HTTP와 HTTPS를 직접 구현해야 했습니다. 다행히도 JSXGetURL이라는 확장 프로그램이 어느 정도 해결해 줬으나, 플러그인을 유료로 판매하는 경우가 많은 그래픽 디자인 도구 시장 특성상, (작업하던 5월 당시에는) 플러그인 개발자께서 6월이 지나면 해당 확장 프로그램의 동작을 멈추게 하고 유료 판매 모델을 도입하려고 했던 것 같습니다. 지금은 해당 시한이 12월로 연기된 것으로 보이는데, 당시에는 사용 시간 제한이 너무 큰 단점으로 다가왔습니다. 7월에도 수정 작업을 해야 할 수 있었으니까요.
그래도 할 수 있는 데까지 한 번 해 보리라 생각했습니다. 다만 여기까지 만든 후 문서화되어 있지 않은 ExtendScript와 JS의 차이점, 그리고 부실한 Illustrator API 문서에 너무 스트레스를 받아서 도저히 더 이상 할 수 없다고 판단했고, 이 방법은 그만뒀습니다.
두 번째 방법 — SVG 생성
ExtendScript로 작업을 했던 이유는 CMYK 색상 공간에서 작업하기 용이해서였습니다. 특히 흰색 잉크 인쇄 레이어는 K100 색상으로 작업되어야 했는데요, CMYK의 K100과 RGB의 #000000은 전혀 다른 색상이기 때문에 이런 부분을 해결해줄 수 있겠다고 생각했기 때문이었음이 가장 큰 이유였습니다.
ExtendScript를 쓸 수 없다면, 이미지를 SVG 형식으로 만들 수 있는지 고민해보기로 합니다. SVG는 벡터 그래픽으로, 이미지를 여러 도형들로 정의하는 표현 방식입니다. Illustrator는 SVG 포맷을 읽을 수 있습니다.
SVG의 색상 공간은 RGB이기는 해서, 흰색 잉크 레이어를 검정색 이미지로 만들면 K100이 나오지는 않는데요, 대신 도형은 색상 변경이 이미지보다 훨씬 편리하기 때문에 Illustrator로 가져온 뒤 K100으로 색상만 바꿔 주면 됩니다.
이제 SVG를 어떻게 자동으로 생성할 것인지만 고민하면 됩니다.
도와주세요, 사토리님!

갑자기 뭔 오타쿠 게임을 들고 오나 싶을 수 있겠는데요, 귀엽고 재밌는 스무고개 게임이니 관심이 있으시다면 꼭 해 보시기 바랍니다. 오타쿠 게임을 통해 힘든 개발 과정을 이겨내고 뭐 그런 건 아닙니다.
예전에 Vercel이 오픈 그래프(OG) 이미지를 생성하는 기능을 추가했다고 홍보한 적 있어서, 기반 기술에 대해 관심을 갖고 찾아본 적이 있습니다.

해당 기술은 HTML과 CSS과 비슷한 문법의 코드를 작성하면 SVG로 바꿔 주는 라이브러리 satori를 기반으로 하고 있습니다. 오픈 소스여서 누구나 쓸 수 있습니다.
OG 이미지에 대한 이야기를 잠깐 하고 넘어가 봅시다. HTML + CSS가 워낙 괜찮은 레이아웃 엔진이라 OG 이미지를 HTML과 CSS 기반으로 만드려는 시도는 많이 있었는데요, 다 좋은데 HTML과 CSS는 너무 기능이 많아서 HTML과 CSS로 OG 이미지를 렌더하려면 브라우저를 켜서 캡쳐해야 했습니다. 자동화는 되지만 꽤 느립니다.
satori는 반면에, 비슷한 문법으로 이미지 렌더에 꼭 필요한 기능들만을 별도의 렌더 방법으로 제공함으로서 브라우저를 켜지 않아도 되게 하여 이 문제를 해결합니다. 아니, HTML이면 HTML이고 CSS면 CSS지 무슨 비슷한 문법일까요?
satori는 React 렌더러입니다. React 렌더러가 무엇인가 하면, 쉽게 말하면 react-native 같은 겁니다. react-native도 JSX 코드를 짜지만 ‘렌더’되면 DOM 트리가 나오는 게 아니라 여러 플랫폼의 네이티브 코드가 나오죠. 이렇게 React는 간혹 DOM 이외의 곳들에서도 쓰이는데, 심지어는 React로 영수증을 생성할 수 있는 프로젝트 react-thermal-printer도 있습니다.
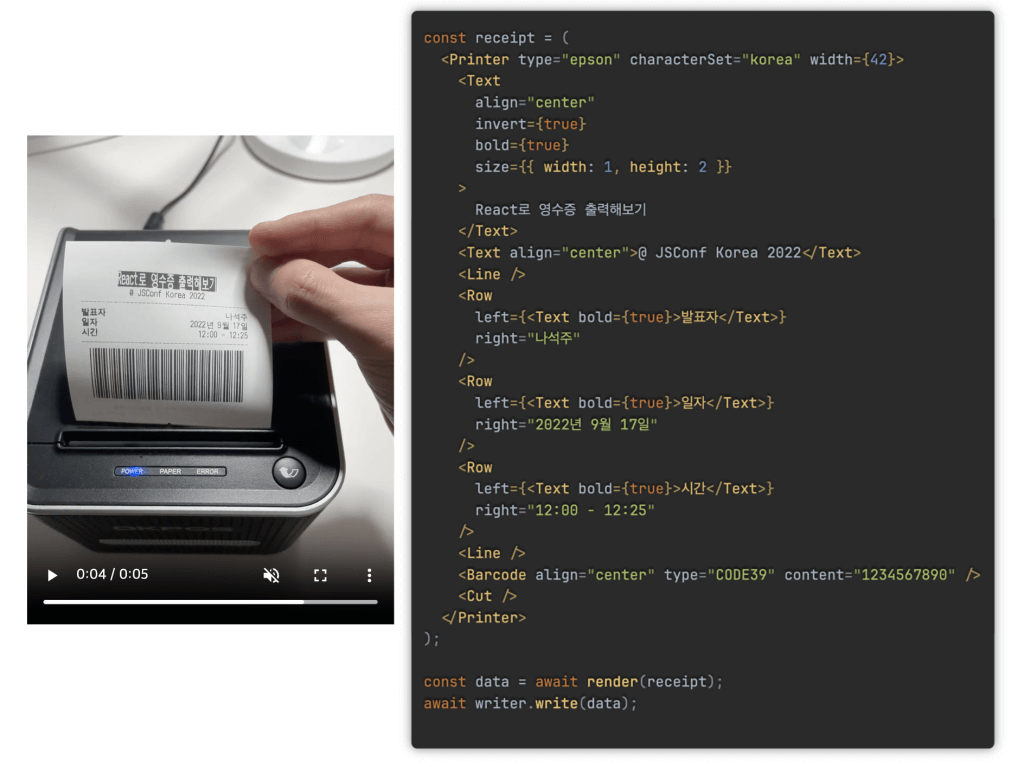
여하튼 satori가 ‘렌더’하는 것은 SVG 코드입니다. 이미지 내 요소들을 프론트엔드 개발자에게는 너무 익숙한 선언적 방법으로 작성할 수 있게 해 주고, flexbox와 최대한 비슷하게 동작하는 자체 레이아웃 엔진을 구현해 친숙한 개발 방법도 챙겼습니다. 이미 JavaScript + React로 많은 걸 짜 왔던 솔브드의 입장에서는 레이아웃 구현의 공수가 낮으리라 예상했습니다. 실제로 solved.ac 프로필 상단부 레이아웃을 satori를 이용해 구현하면 이렇게 됩니다.

<span
style={{
fontSize: 48,
fontWeight: 700,
}}
>
{handle}
</span>
{badge !== null && (
<img
src={badge.badgeImageUrl}
style={{
width: 64,
height: 64,
filter: 'drop-shadow(0 8px 8px rgba(100, 100, 100, 0.3))',
marginLeft: 12,
}}
/>
)}
<img
src={classImgUrl(classValue, classDecoration)}
style={{
width: 72,
height: 72,
}}
/>
정말 편하게 레이아웃을 구성할 수 있었습니다. 모든 과정이 순탄합니다.
자동 생성을 고려해 봅시다. 저번에 ExtendScript로 했던 방식과 다르게 이제 아예 서버에 적당한 파라미터로 GET 요청을 보내면 서버에서 SVG 코드를 계산해 주도록 합니다. 이제 주문 목록을 기반으로 서버에 이미지 생성 리퀘스트를 보내고, 서버가 보내온 SVG를 어딘가 저장하는 스크립트를 짜면 자동 생성 완료입니다. 그런 고로, 위에 적은 코드는 솔브드의 클라이언트에 있는 코드가 아니라 API 서버에 있는 코드입니다.
이제 특정 URL에 주문번호만 넣으면 해당 주문번호의 굿즈를 자동 생성해 줍니다.
앞서 말했듯이 걱정했던 것들 중에 폰트 문제도 있었는데요, 웹 폰트 환경과 디자인 프로그램에서의 폰트 환경은 약간 달라서 변환이 필요할까도 고민이었는데, 스크린샷을 보시면 아시겠지만 satori가 텍스트를 애초에 모양을 따서 도형으로 렌더해 줘서 이런 고민이 필요없었습니다. 폰트를 읽는 정도의 능력이라니 대단하군요. 이제 이걸 Adobe Illustrator에 가져오기만 하면 됩니다.

일반적인 Express.js 프로젝트에서 이런 디펜던시를 보게 될 일이 얼마나 있을까요?
난관
그러나 당연하게도 이런 일반적이지 않은 작업이 순탄할 리가 없습니다.
Adobe Illustrator는 SVG를 지원합니다. 적어도 저는 그렇게 알고 있었습니다. 하지만 막상 파일을 가져오려고 해 보니 뭔가 불길한 경고가 뜹니다.
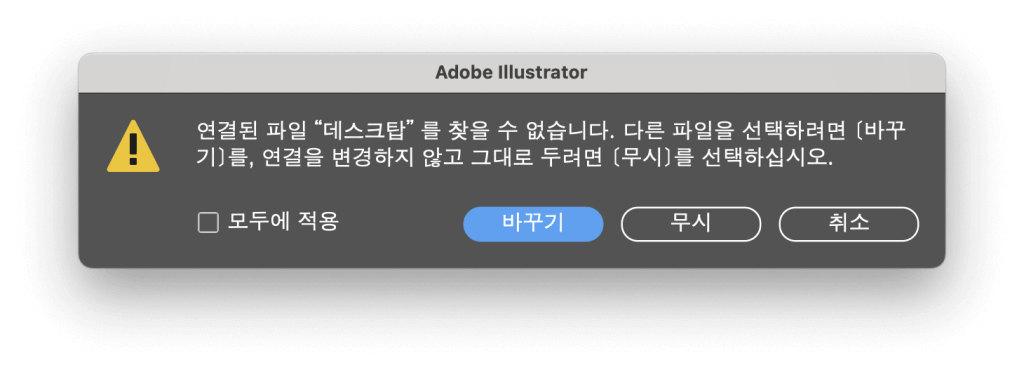
무슨 일이 일어날까요? 정말 기대가 됩니다.
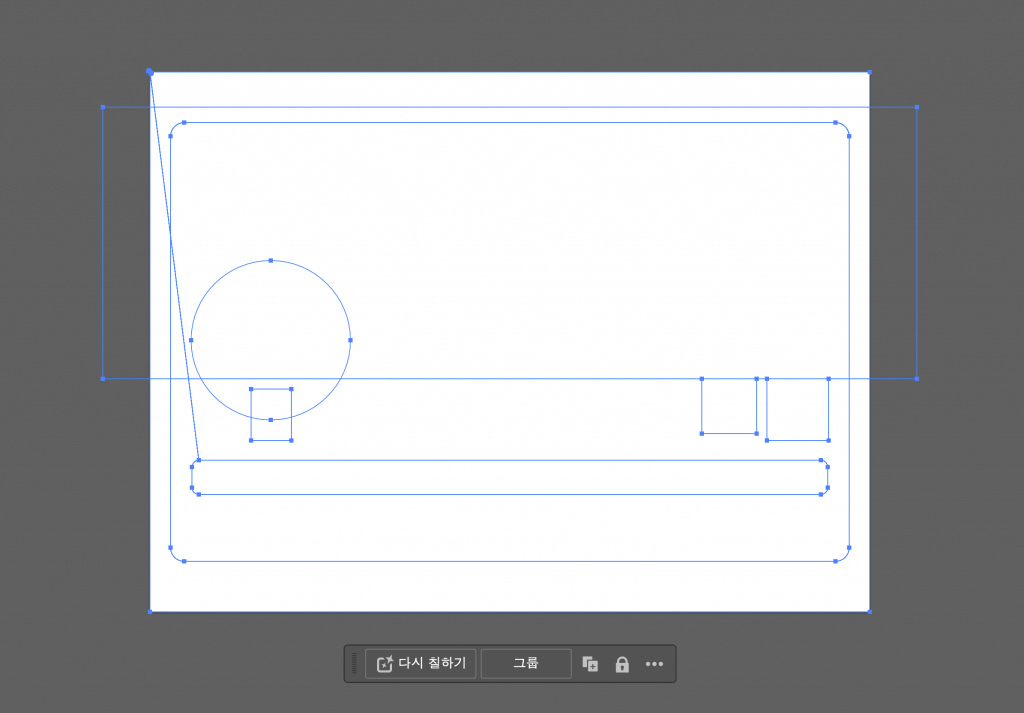
오…
Illustrator는 제가 열심히 만든 SVG는 전혀 읽지 못하는 기염을 보여줍니다.

알아보니까 Illustrator는 SVG의 <mask> 요소를 그렇게 좋아하지 않는 것 같습니다5,6. 게다가 <image> 요소의 이미지 URL을 나타내는 src 속성에 Base64로 표현된 이미지가 있는데, 브라우저는 완벽하게 읽어 주지만 Illustrator는 이게 무슨 말인지 모르는 것 같아 보입니다.
SVG의 구조를 변경할 수 있을까 싶어서 satori가 생성한 SVG를 열어봤는데 <mask> 요소 없이는 아무것도 그리지 못할 것 같은 구조였습니다. 막다른 길을 만난 걸까요?
세 번째 방법 — PNG 생성
애초에 이런 고민들을 했던 이유는 마스크가 K100이어야 하기 때문이었습니다. 굳이 SVG가 아니더라도 RGB 색상 공간의 이미지를 불러와 CMYK의 K100으로 바꿀 수 있는 기능이 Illustrator에 있으면 됩니다. 메뉴 이곳저곳을 뒤져보다가 뭔가 그럴싸한 메뉴를 발견했습니다. ‘편집 > 색상 편집 > 회색 음영으로 변환’이었습니다.
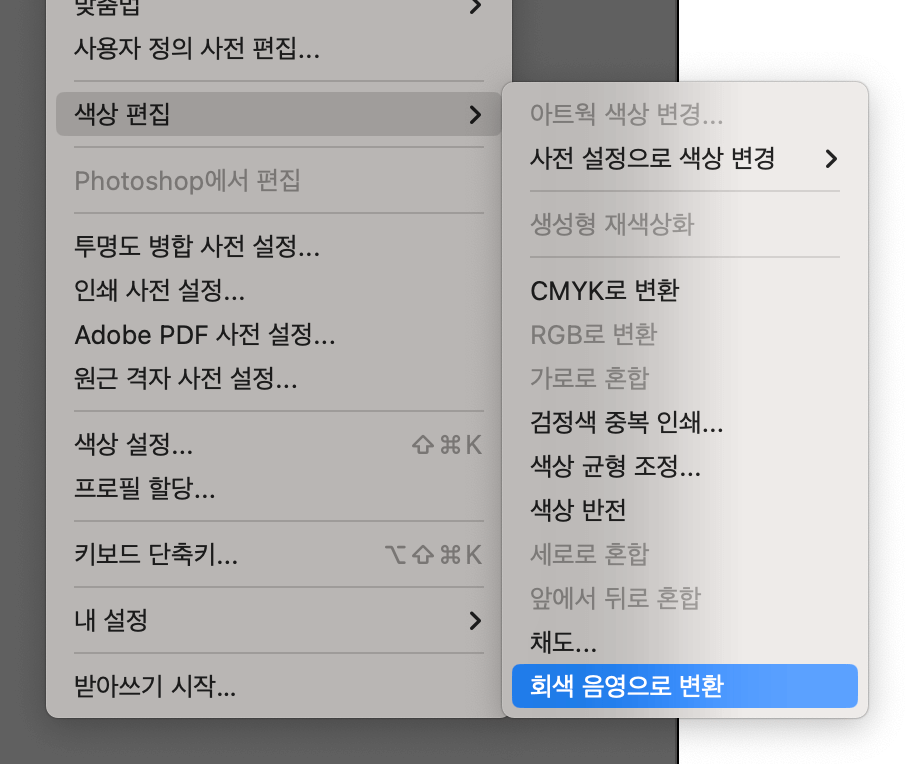
CMYK 모드의 문서에서 ‘회색 음영’이 뜻하는 건 단 하나밖에 없을 것 같습니다. 속는 셈 치고 눌러 봅시다.
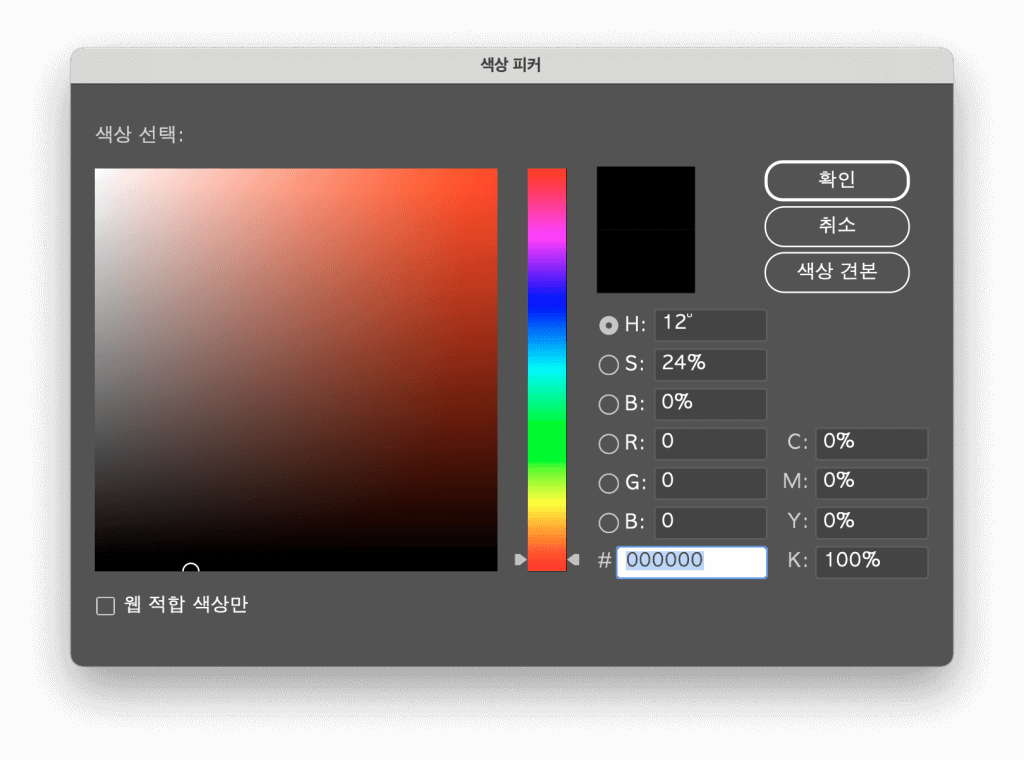
성공했습니다. 완벽한 K100입니다. 진작 메뉴부터 뒤져볼 걸…
뭔가 처음 생각했던 개발 방법과는 많이 달라진 느낌이 없지 않지만 여하튼 이제 정말로 굿즈를 자동 생성하기 위한 모든 퍼즐 조각이 모였습니다. 이제 맞추기만 하면 됩니다.
resvg를 사용하면 SVG를 PNG로 렌더할 수 있습니다. Express 서버에 아래 네 줄만 추가해 주면 됩니다. 다만 역시 PNG 렌더 과정이 추가되니 SVG보다는 다소 느렸습니다.
const resvg = new Resvg(svg, opts)
const pngData = resvg.render()
const pngBuffer = pngData.asPng()
res.contentType('image/png').send(pngBuffer)
이제 정말로 자동화에 돌입합니다. Illustrator에는 ‘변수’라는 기능이 있습니다. CSV로 ‘데이터 세트’를 정의하면 여기에 저장된 값을 그대로 가져다 쓸 수 있고, 각 데이터 세트마다 어떤 매크로를 실행하게 할 수 있습니다. 약간 디자이너 버전 forEach 함수 같은 느낌입니다.
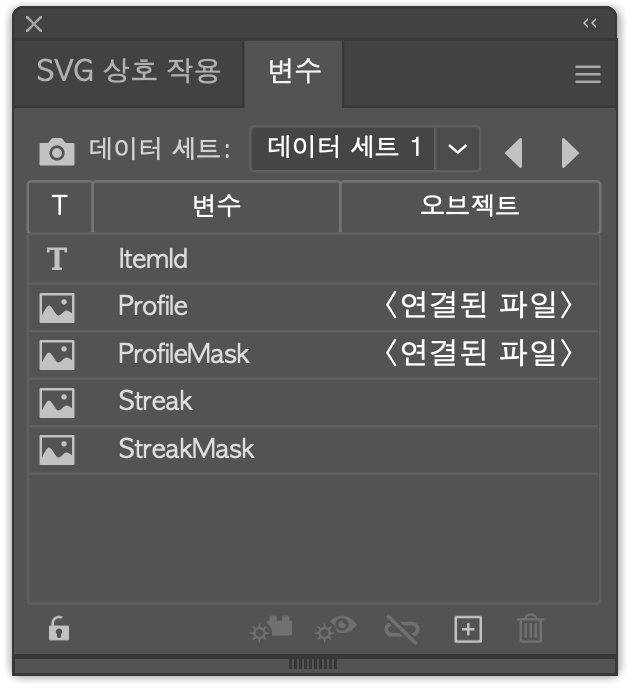
데이터 세트의 변수 유형으로는 이미지도 있습니다. 파일시스템 내의 경로를 CSV 파일 내에 정의해 주면 됩니다. 예를 들어 이렇게요.
ItemId,@Profile,@ProfileMask,@Streak,@StreakMask 41,/Users/shiftpsh/merch-generate/images/41_profile.png,/Users/shiftpsh/merch-generate/images/41_profile_mask.png,/Users/shiftpsh/merch-generate/images/41_streak.png,/Users/shiftpsh/merch-generate/images/41_streak_mask.png 60,/Users/shiftpsh/merch-generate/images/60_profile.png,/Users/shiftpsh/merch-generate/images/60_profile_mask.png,/Users/shiftpsh/merch-generate/images/60_streak.png,/Users/shiftpsh/merch-generate/images/60_streak_mask.png 103,/Users/shiftpsh/merch-generate/images/103_profile.png,/Users/shiftpsh/merch-generate/images/103_profile_mask.png,/Users/shiftpsh/merch-generate/images/103_streak.png,/Users/shiftpsh/merch-generate/images/103_streak_mask.png
일단 이런 CSV를 생성해 주는 Python 스트립트를 만들었습니다. 대충
- 주문 목록을 가져오고
- 하나의 주문 당 한 번, Express 서버에 아크릴 이미지 파일 생성 요청을 보내고, 그걸 PNG로 저장
- 저장된 파일의 절대 경로를 CSV에 작성
하는 코드입니다.
def main():
rows = read_file()
print(f"Found {len(rows)} orders")
count = 0
with open('s2_2023_merge.csv', 'w') as csvfile:
writer = csv.writer(csvfile)
writer.writerow([
"ItemId",
"@Profile", "@ProfileMask",
"@Streak", "@StreakMask"
])
for row in rows:
count += 1
print(f"Downloading images for order {row[0]}... ({count}/{len(rows)})")
item_id = row[0]
order_id = row[1]
writer_out = [item_id]
for image_id in image_ids:
filename = f"images/{item_id}_{image_id}.png"
filename_mask = f"images/{item_id}_{image_id}_mask.png"
download_and_save_image(image_url(order_id, image_id, item_id, False), filename)
download_and_save_image(image_url(order_id, image_id, item_id, True), filename_mask)
writer_out.append(filename_prefix + filename)
writer_out.append(filename_prefix + filename_mask)
writer.writerow(writer_out)
이렇게 생성된 CSV 파일을 Illustrator에 넣어 줍니다. ‘변수 > 변수 라이브러리 불러오기…’를 선택하면 데이터 세트를 불러올 수 있습니다.
이제 이미지를 로드한 직후 저장 직전까지 수행할 작업들을 ‘액션’으로 정의합니다.
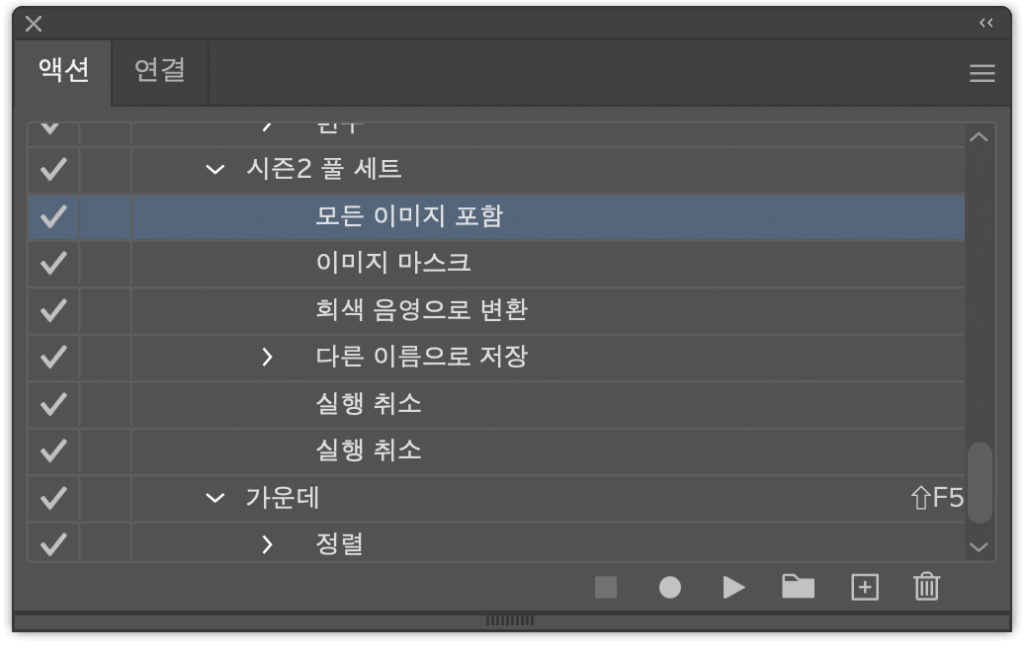
할 일들을 액션으로 정의하면 ‘액션 > 일괄 처리’를 통해 데이터 세트에 대해 앞서 언급한 forEach 같은 걸 돌릴 수 있게 됩니다. 제 경우에는 두 번째 캔버스에 그려지는 마스크의 검정색(#000000)을 K100으로 바꿔야 했기 때문에 ‘회색 음영으로 변환’을 넣어 줬습니다.
이제 정말로 굿즈가 자동 생성됩니다! 작업을 돌려 놓고 쉬다 오면 생성이 완료될 겁니다. 생성 완료된 파일은 인쇄소에 바로 전달할 수 있는 형태입니다.
발주

엄청난 박스들이 왔습니다. 잠잘 공간만 겨우 남긴 채로 5일 동안 포장을 했습니다.
뒤늦게 깨달은 실수
이상한 점을 찾아봅시다.
2023년 6월 5일 오전 6시를 기준으로 생성해야 하는 프로필 그래픽이 무슨 이유에서인지 2023년 6월 4일 오후 9시를 기준으로 생성되었습니다. 대체 왜일까요?
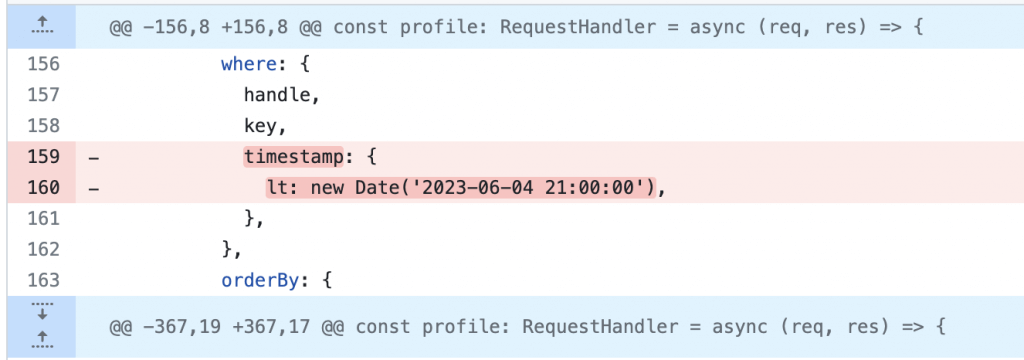
한국 시각 오전 6시니까 UTC 기준 전날 오후 9시인 건 맞는데, 크게 간과한 부분이 있습니다. 위의 코드는 틀렸습니다. 대신 아래와 같이 적어야 합니다.
new Date('2023-06-04T21:00:00Z')
// or
new Date('2023-06-05T06:00:00+09:00')
로컬에서 서버를 돌렸기 때문에 당연히 시간대를 표시하지 않았으니 저 줄은 한국 시각으로 해석되고, 9시간 앞선 데이터로 굿즈를 만들어 발주하게 된 것입니다. NASA가 인치와 센티미터를 헷갈려서 위성을 추락시킨 사례를 처음 듣고 웃어넘겼는데 그런 기관이 할 수 있는 실수라면 저도 마땅히 할 수 있는 것이었습니다. 오만해지지 말아야 합니다. 네.
인쇄 사고가 발생한 굿즈를 전량 다시 제작했고 다시 보냈습니다. 결국에 굿즈 샵 캠페인을 열고 남은 건 없습니다. 여러분이 남습니다.
짧은 소감
이외에도 굿즈 샵 개최를 위해 결제모듈을 연동하고 쇼핑몰 시스템을 자체 제작하는 등 해 보지 않았던 시도들을 해 보면서 재밌게 개발했습니다. Express 프로젝트에 React 설치해서 굿즈 자동화 하는 건 여태까지 듣도 보도 못한 개발 과정이고 어디서도 해보지 못할 경험인 것 같습니다.
서버비에 도움이 될까 기대했는데 이 부분에서는 너무 큰 실수를 해서 안타깝고 아쉽습니다. 아무리 테스트와 점검이 귀찮고 힘들고 오래 걸리더라도 이렇게 중요한 일을 하기 전에는 제대로 점검해야겠다는 생각을 하게 된 계기를 마련하게 되었습니다. 위성 추락보다는 싸게 배웠으니 다행입니다.
끝으로 솔브드에 많은 관심 가져 주셔서 항상 감사드립니다!
각주
- https://www.typescriptlang.org/tsconfig#target ↑
- https://www.typescriptlang.org/docs/handbook/2/basic-types.html#downleveling ↑
- https://www-archive.mozilla.org/js/language/e262-3.pdf, 168쪽 ↑
- https://community.adobe.com/t5/after-effects-discussions/extendscript-throws-on-nested-ternary-operator/m-p/9573874 ↑
- https://community.adobe.com/t5/illustrator-discussions/illustrator-does-not-understand-svg-masks/m-p/12408862 ↑
- https://github.com/MakieOrg/Makie.jl/issues/882 ↑