제목이 곧 내용, 올해 서강대학교 교내대회를 개최했습니다. 제가 출제와 운영을 총괄했습니다! 진짜 구데기컵 2018(…)을 제외하면 제 첫 출제였고, UCPC 2018에 풍선 스탭으로 참여한 걸 제외하면 첫 운영이었습니다. 대회를 준비하고 진행하면서 느낀 점들을 적어보려 합니다.
어떤 걸 먼저 해야 하지
서강대학교의 경우 2005년부터 매년, ICPC Korea Regional에서 교내 랭킹 1~2위의 팀이 대회 운영과 출제를 해왔습니다. 대회는 보통 11월 말이고 ICPC 본선은 11월 초에 진행되기 때문에 보통 2~3주 정도의 준비 기간이 주어집니다. 아니 대회 운영하려면 뭐가 필요한지도 모르는데 2주만에 대회 준비를 어떻게 해요??
근데 사람 일이 다 그렇듯이 놀랍게도 대회 날짜가 다가오면 준비를 하게 되어 있더라고요. 학교에서 ICPC 본선에 3팀이 출전했는데, ‘그래도 우리 팀이 그 중에서 적어도 2위는 하겠지?’ 라는 행복회로를 돌리면서 김칫국 109 + 7사발 마시고 미리 대회 개최를 준비했습니다.
대회를 열기 위해 필요한 것들은 대략 다음과 같습니다.
- 문제. 문제 푸려고 여는 대회인데 문제가 없으면 안 되죠.
- 출제진. 애초에 출제진이 없으면 문제가 나올 수가 없죠.
- 검수진. 물론 출제진이 검수해도 괜찮습니다.
- 시간과 공간. 언제 어디서 개최할지 결정해야 합니다.
- 참가자. 이건 제가 어쩔 수가 없고..
- 포스터, 풍선, 간식 같은 거
이 중에 제가 그 시점에 할 수 있었던 건 문제 만들기였습니다. Redshift가 본선 교내 1~2등 안에 들면 세 명 모두 출제를 해야 했기에, 일단은 팀 내에서 문제를 뭐 낼지 어렴풋이 생각해 보기로 했습니다. 대충 이런 문제 아이디어가 나왔습니다.
- 7-세그먼트 디스플레이 (shiftpsh 아이디어)
- 개인적으로 좋은 문제라고 생각했어서 제네레이터까지 만들어 뒀습니다.
- 올솔브 방지용 graph isomorphism 문제 (shiftpsh 아이디어)
- Tree isomorphism 문제로 약화되어 출제되었습니다. 이거 오렌지 이상에선 웰노운이라더라고요. 왜 내가 웰노운이 아니라고 생각했던 건 다 웰노운이지??
- 최단 경로 문제인데, 길이의 곱이 최단이 되어야 하기 때문에 간선 가중치에 전부 로그를 씌워 구하는 문제 (lvalue 아이디어)
- 방콕 리저널 예비소집일에 나온 아이디어였는데, 다음날 본대회 F번?으로 실제로 나와버렸기 때문에 표절 의혹을 받을까봐 실제 대회에는 못 냈습니다.
- 이 아이디어 덕분에 대회 당시 F번을 두번째로 빨리 푼 팀이 우리 팀이었는데, 역설적이게도 대회를 말아먹는 계기가 되었습니다. 이건 다른 포스트에 후술.
다행히도 Seoul Regional에서 교내 1등을 하는 데 성공했기 때문에 대회 운영에 참여할 수 있게 되었고, 이제 아까 언급한 ‘대회 운영에 필요한 사항’ 4개 전부를 고려해야 하는 상황이 되었습니다.
문제
각자 내고 싶은 문제들은 있겠지만, 실제로 모두가 각자 내고 싶은 문제만 낸다면 프로그래밍 대회가 아니라 빡구현 코딩테스트가 될 수도 있고, 고인물 자료구조 파티가 될 수도 있고, 계산수학 경시대회가 될 수도 있겠다고 생각했습니다. 그래서 아래와 같은 원칙을 두고 대회 문제들의 전체적인 틀을 정했습니다.
- 출제되는 문제들의 주제는 균형적이어야 합니다.
- 12문제 중 DP가 5문제고 그러면 좀.. (ICPC Seoul 예선 출제자님 듣고 계신가요)
- 모든 문제를 푸는 사람은 없어야 하고 하나도 못 푸는 사람이 있어서는 안 됩니다.
- ICPC 출제 기조라고 들었습니다.
개인적으로는 tree isomorphism 문제를 너무 내고 싶었기 때문에 디비전 당 8문제, 총 16문제를 내기로 정했습니다. 지금 생각해보면 그러지 말거나 아니면 디비전끼리 겹치는 문제를 내게 하거나 했어야 했는데 아무튼 그렇게 정했습니다.
구데기컵에서 문제 정리를 위한 스프레드시트를 팠던 기억이 있어서 저도 그렇게 했습니다.
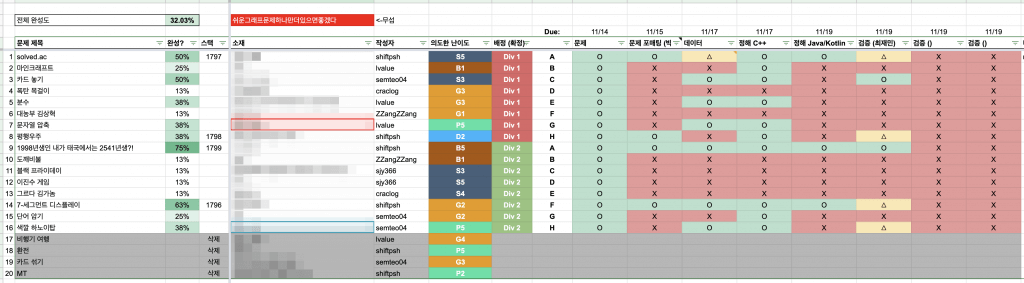
20문제를 낸 후, 각각 solved.ac 기준 예상 난이도와 사용 알고리즘/자료구조를 적고 8개 문제씩 Champion/Master에 각각 배정해나가면서, 대회가 너무 어려워질 것 같아서 많이 등장한 주제의 문제 중 4문제를 뺐습니다. 그리고 동그라미를 하나씩 채워나가는 방향으로 문제를 준비했습니다.
예상 난이도를 정하는 것에 장점과 단점이 있었는데요,
- 장점은 문제를 배정하기가 쉬웠다는 점이었고,
- 단점은 문제 난이도를 잘못 예상해서 Master 디비전 스코어보드가 망했다는 점이었습니다.
- 출제자 생각과 참가자 생각은 많이 다르다는 걸 깨달았고, 조금 더 참가자 입장에서 문제 난이도를 생각해 보려고 노력해야겠다고 느꼈습니다.
문제들을 배정하고 나서는 스테이트먼트와 정해 – 데이터와 테스트 – 제한 순서대로 문제를 만들었습니다.
스테이트먼트
참가자 입장에서 스테이트먼트는 명료할수록 좋습니다. 러시아의 모 사이트에서 열리는 대회에는 스테이트먼트가 애매하거나 이상한 경우가 종종 있었는데, 이로 인해 스트레스를 받은 경험이 있었기 때문에, 참가자가 문제를 푸는 데 방해가 되지 않도록 스테이트먼트를 구성하려고 노력했습니다. 출제 의도가 스테이트먼트를 길게 해서 일부러 문제풀이를 지연시키고자 하는 게 아니라면 쓸데없는 이야기는 줄이고 문법상의 오류나 비문은 최대한 없애고, 문장은 짧게 구성하도록 하고. 사실 글쓰기의 기본이죠.
아래는 카드 놓기의 스테이트먼트 원고와 최종본을 비교해 둔 것입니다.
| 첫번째 줄에는 N(1<=N<=1000000)이 주어진다. 두번째 줄에는 길이가 N인 수열 A가 주어진다. Ai가 1이면 i번째로 카드를 내릴 때 1번 기술을 썼다는 뜻이다. Ai가 2이면 i번째로 카드를 내릴 때 2번 기술을 썼다는 뜻이다. Ai가 3이면 i번째로 카드를 내릴 때 3번 기술을 썼다는 뜻이다. Ai는 1,2,3중 하나임이 보장된다. An은 항상 1임이 보장된다. |
| 첫 번째 줄에는 N (1 ≤ N ≤ 106)이 주어진다. 두 번째 줄에는 길이가 N인 수열 A가 주어진다. Ai가 x이면, i번째로 카드를 내려놓을 때 x번 기술을 썼다는 뜻이다. Ai는 1, 2, 3 중 하나이며, An은 항상 1이다. |
위와 아래 중 어떤 글이 더 이해하기 쉬운가요? (아래라고 해주세요)
- 1000000은 한 눈에 봤을 때 정확히 얼마인지 가늠하기 어렵기 때문에, 1,000,000 또는 106으로 고쳐야 합니다.
- <=은 정확한 표현이 아니기 때문에 ≤으로 고칩니다. 변수명은 일반적인 글과 구분하기 쉽게 하기 위해 기울임꼴으로 씁니다. 기울임꼴로 하는 편이 실제 수식에서 등장하는 문자들의 모양과 비슷하기도 하고요.
- 쉼표로 나열된 항목들은 띄어쓰기로 구분해 줍니다(1,2,3 → 1, 2, 3).
- 같은 의미의 글이 여러 번 반복되는 경우 간단하게 줄일 수 있는지 생각해 봅니다.
스테이트먼트를 그냥 읽어보면 모르겠지만, 계속 긴장 상태일 참가자 분들의 입장에서 편하게 읽힐 수 있도록 이렇게 나름대로 세심하게 편집하는 작업을 거쳤습니다.
또한 글만 적혀 있으면 문제를 이해하는 데 어려움이 있을 수도 있기 때문에 몇몇 문제에는 적절한 위치에 삽화들을 그려서 삽입했습니다. 다행히도 제가 그래픽 디자인을 할 줄 알았기 때문에 삽화는 제가 전부 그렸습니다.
정해
출제자의 정해가 틀리면 안 됩니다. 최근 열렸던 학교 대회 중에 출제자가 잘못된 풀이를 작성한 경우가 종종 있었고, 서강대학교만 해도 2017년에 출제자가 정해를 잘못 작성했던 적이 있었습니다. 특히 대회 준비 중에 열린 타 대학교 대회에서 이런 상황이 발생했기 때문에 각별히 신경써서 검수했습니다.

학과에서는 외부 검수자를 초빙하지 말라고 했지만 2주 안에 16문제를 출제해야 하는데 출제 경험이 적은 6명이 오류를 안 내는 게 이상한 상황이었고, 결정적으로 스타트링크에서 검수자 초빙을 말 그대로 강력하게 권장했기 때문에 제 단독 판단으로 검수자를 초빙하기로 했습니다. 여러 대회에 검수자로 참가했던 분들이었기에 문제 보안에 대해서는 믿을 수 있었으며, 개인적으로는 잘못된 문제를 만들지 않는 것이 더 중요하다고 생각했기 때문입니다.
아니나다를까 색깔 하노이 탑 문제에서 출제자의 정해가 잘못되었음이 외부 검수자에 의해 발견되어 일찍 수정할 수 있었습니다. 검수자 분들께서는 후술할 데이터와 시간 제한에 대한 검증도 진행해 주셨습니다. 외부 검수자 분들께서 안 계셨다면 이번 대회도 문제 오류가 있는 대회가 될 뻔 했는데, 참 다행이라고 생각합니다. 이 글을 빌어 감사하다는 말씀을 다시 한 번 전해드리고 싶습니다.
데이터와 테스트
저는 Polygon을 이용해 데이터를 만들었습니다. Polygon은 Codeforces에서 프로그래밍 문제 제작을 도와주는 목적으로 만든 플랫폼입니다. 다음과 같은 것들이 가능합니다.
- 데이터 생성 및 관리
- 입출력 형식 검증
- 출력 가능한 스테이트먼트 PDF 제작
특히 입력 형식의 무결성은 상당히 중요하기 때문에 Polygon을 사용합니다. 예를 들어 평행우주는 입력이 다음 조건을 만족함이 보장되어야 합니다.
- 입력으로 들어오는 각각의 그래프는 연결되어 있어야 하며 트리여야 합니다. 노드가 s개라면 노드 번호는 0, 1, 2, …, s − 1로 주어져야만 합니다.
- 입력으로 들어오는 트리의 개수는 106개 이하여야 합니다. 각 트리의 노드의 개수는 30개 이하여야 합니다. 또한 모든 트리의 노드 개수의 합도 106개 이하여야 합니다.
- 당연하겠지만, 입력의 각 줄마다 맨 앞이나 맨 뒤에 공백 문자가 있어서는 안 되고, 공백이 두 개 들어가 있다거나, 맨 마지막 줄에 줄바꿈이 없다거나 하는 경우도 안됩니다. C/C++로는 어찌저찌 잘 풀릴지도 모르지만 Java와 Python에서 제대로 풀리지 않을 수 있기 때문입니다.
testlib.h는 위와 같은 무결성 체커를 간단하게 짤 수 있도록 해 줍니다. 또한 Polygon은 이렇게 짠 무결성 체커를 바탕으로 데이터를 제작할 때 모든 데이터에 대해 생성과 동시에 자동으로 무결성 체크를 해 주기 때문에 다른 더 중요한 것들에 집중할 수 있게 해 줍니다.
testlib.h는 데이터 생성기를 제작할 때도 사용할 수 있습니다. 안타깝게도 다른 출제자 분들께서는 Polygon 사용 경험이 없었고, 출제 시간도 2주로 상당히 촉박해서 급한 대로 testlib.h를 쓰지 않는 제네레이터를 만들었습니다. 실제로 도중에 입력 조건에 맞지 않는 데이터가 업로드되었는데, 무결성 체커가 없어서 찾아내기 어려웠습니다. 다행히도 대회 직전에 찾아서 삭제했습니다.
하지만 Polygon 자체도 문제 제작자가 짠 코드에 의존하기 때문에, 대부분의 실수를 잡아낼 수 있다고 하더라도 잡아내기 어려운 실수들도 있습니다. 가령 평행우주의 경우는 날 새가면서 정신없이 문제를 만들다 보니 제가 10만과 106을 헷갈렸나 봅니다. 문제에는 별의 수와 별자리의 수가 106을 넘지 않는다고 되어 있습니다만 실제로는 각각이 105을 넘지 않는 약한 데이터만을 준비했던 사실을 시상식 때가 되어서야 깨달았습니다.
데이터 자체는 무결했으니 문제나 데이터의 오류는 아니었지만, 의도하지 않은 풀이가 통과할 수도 있었던 상황이었습니다. 대회 당시 맞은 사람이 없었어서 다행이었을까요? 곧 데이터를 추가할 예정입니다.
제한

의도한 풀이는 통과하고, 의도하지 않은 풀이는 통과하지 않도록 제한을 잘 설정해야 합니다. 그런데 이게 은근 어려운 게,
- 언어마다 실행 시간에 차이가 있습니다.
- Python에서 최적의 솔루션이 동작하는 시간이 C++에서 나이브한 솔루션이 동작하는 시간보다 느릴 수도 있습니다.
- 같은 언어의 같은 풀이라도 입력 방식에 따라 실행 시간에 많은 차이가 생깁니다.
- 느린 입력 방식 기준으로 시간 제한을 설정하면, 빠른 입력 방식을 사용했지만 느린 알고리즘을 사용한 코드가 시간 안에 통과하는 상황이 생길 수도 있습니다.
solved.ac는 어떤 방식으로 정렬을 해도 괜찮은 문제이지만, 원래는 인덱스 소트를 이용해 O(n)으로 정렬해야만 하는 문제로 기획되었습니다. 그래서 기존에는 제한이 n ≤ 107이었습니다. 하지만 C++에서 빠른 입력을 쓰고 std::sort를 사용한 코드가 500ms 좀 넘게 돈 반면, Java에서 인덱스 소트를 이용한 코드가 800ms가 나오길래, 그냥 포기하고 쉽게 바꿨습니다.
작년 대회와 다르게 이번 대회에서는 Python을 사용할 수 있도록 했지만 정작 모든 문제가 Python으로 풀릴 것이라고 보장하지는 않았습니다. 대회 규칙에는 ‘출제진이 모든 문제를 C++과 Java 혹은 Kotlin으로 풀었음이 보장됩니다’라고 적었고, 실제로 C++과 Java 혹은 Kotlin으로 모든 문제를 검증했으나 Python으로는 풀리지 않는 문제도 있었습니다. Python은 현저히 느리기 때문에 Python 기준으로 시간 제한을 잡으면 C++ 나이브 코드가 통과할 수도 있기 때문이었습니다. 이는 ICPC World Finals 규칙과도 같습니다.
메모리 제한은 전부 1024MB로 설정했습니다. 여러 테스트를 돌려 보면서 틀린 코드가 맞거나 맞은 코드가 틀리는 등의 상황이 발생하면 제한을 조절하거나 데이터를 보강하는 등의 작업을 진행하면서 문제를 완성시켜 나갔습니다.
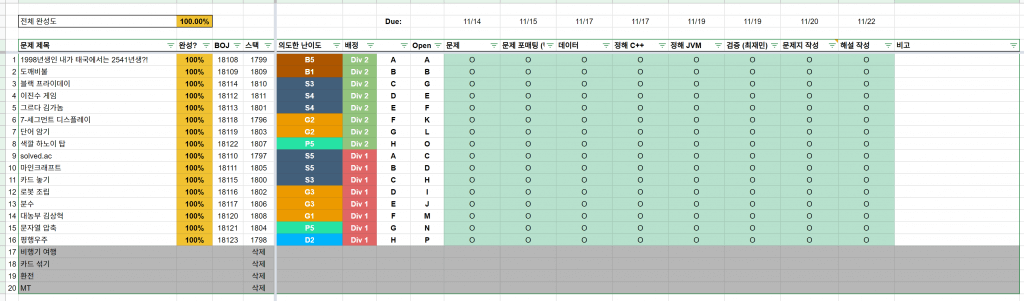
그렇게 시트를 전부 동그라미로 만든 후에는 한 숨 돌릴 수 있었습니다.
운영
문제를 다 만들어갈 때쯤에는 대회 운영에 대한 것도 생각해야 했습니다. 다행히도 학과에서 다년간 대회 운영을 도와주고 계셨기 때문에 이런 것들은 별 고민 없이 해결되었습니다.
대회 진행 전
- 장소. 실습실은 학교가 관리하고 있기 때문에 대여도 학과에서 처리해 주셨습니다.
- 풍선. 역시 학과에서 지원해 주셨습니다.
- 헬륨 풍선이 생각보다 비쌌습니다. 하나에 1,500원이었는데, 대회 끝나고 못 나눠준 풍선은 다 터뜨려야 한다고 생각하니 좀 안타까웠습니다.
- 간식. 이것도 학과에서 지원해 주셨습니다.
포스터는 학과에서 인쇄만 해 주기 때문에 제가 만들어야 했습니다. 팀노트에 있던 디닉 코드를 가져와서 3시간동안 간단히 만들었습니다.


학내 이곳저곳에 포스터를 붙이고, 참가자는 학교 커뮤니티에 게시글을 올려 모집했습니다. 총 91분께서 참가 신청을 해 주셨습니다. 안타깝게도 당일에 안/못 오신 분들이 많아서 실제 대회 당일에는 약 70분 가량 참여해주셨습니다.

문제지도 만들었습니다. 문제지는 LATEX로 타입세팅해 대회 전날에 인쇄했습니다. 학과사무실에서 인쇄해 제본과 운반을 전부 수작업으로 했는데, 대회 운영 중 가장 힘들었던 일이 아니었을까 싶습니다.
대회 당일

대회 당일 운영은 순조로웠습니다. 다만 실습실에 PyCharm과 IntelliJ를 설치하느라 시간이 오래 걸렸는데, 전날에 미리 설치해 뒀다면 좋았겠다 싶었습니다. 실습실이어서 학생들이 작성한 코드가 남아 있었고 이들을 전부 지우기 위해 현장에서 배치 파일(.bat)을 급조해 모든 컴퓨터에서 돌렸습니다.

풍선을 나눠주려면 자리표가 있어야 편한데 이 사실을 간과했습니다. 자리표도 현장에서 가나다순으로 급조했습니다. 이런저런 일들로 인해 대회 초반에 풍선이 늦게 나가는 일이 있었습니다.
Champion 디비전은 별 일이 없었지만 Master 디비전 스코어보드는 꽤 오랫동안 많은 사람들이 1솔브에서 머물러 있었습니다. B번 문제의 난이도를 잘못 생각했음을 직감했습니다. 다음날 진행된 Open Contest에서도 B번 문제가 많이 풀리지 않았습니다. 심지어 ainta님은 A~P를 전부 푼 후 마지막에 B를 푸셨을 정도.
많은 사람들이 겹받침이 등장할 때 도깨비불 현상이 일어난다는 걸 간과한 듯했고, 대회가 시작한 후 꽤 지나서 공지사항으로 추가 테스트 케이스를 제공했습니다. 이 테스트 케이스 덕분에 B를 맞게 된 분들이 몇 분 계셨지만 애초에 Master B번으로 낼 만한 수준의 문제가 아니었다는 걸 생각하지 못했던 건 아쉬움으로 남습니다. 초보자에게 문자열 처리는 생각보다 어려운 주제인가 봅니다.
대회 운영진은 참가자의 소스코드를 전부 읽어볼 수 있기 때문에, 채점 현황에서 여러 코드를 읽어봤습니다. 혹시 맞는 코드인데 틀린 건 아닌지, 틀린 코드인데 맞은 건 아닌지 등을 확인하기 위해서입니다. 코드를 확인하다 보니 cout << fixed를 하지 않아 문제를 아깝게 틀린 경우도 있었습니다. 안타까웠지만 어쩔 수 없었습니다.. 다행히도 틀린 코드가 통과하거나 맞은 코드가 통과하지 않는 경우는 없었습니다.
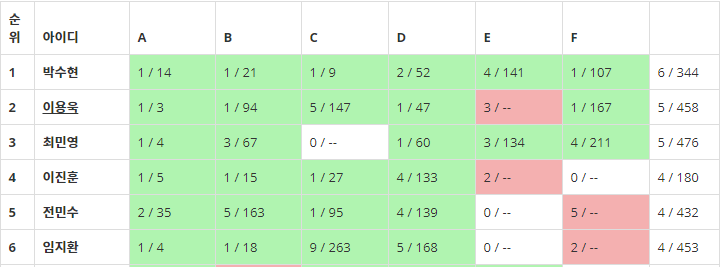
Master는 A, B, D, G, H의 5문제가, Champion은 A, B, C, D, F의 5문제가 각각 풀렸습니다. Champion 쪽은 제가 예상한 대로였으나 Master에서 문제가 많이 풀리지 않아 아쉬웠습니다. 과연 모두 재밌게 즐길 수 있을 만한 대회였을까요? Champion은 그랬던 것 같습니다. 안타깝게도 Master는 난이도 예상을 너무 잘못했던 것 같습니다.
이후 오픈 콘테스트도 순조롭게 진행되었고, 문제 오류는 딱히 없었기 때문에 바로 문제들을 공개했습니다. 제가 출제해 제일 어려운 문제로 기획했던 평행우주가 문제 공개 후 (고인물들에게) 나름대로의 인기를 끌고 있어 뿌듯합니다. 그렇다고 내년 ICPC Seoul Regional에 tree isomorphism이 나오는 걸 보고 싶진 않은데요.. 뭐 여하튼.
대회 운영과 문제 출제가 생각보다 어려운 것임을 깨닫게 해 준 계기가 되었습니다. 좋은 대회를 여는 건 정말 힘들다는 것도요. 생각해야 될 게 정말 많았습니다. 제가 했던 고민들이 대회를 여시려고 하시는 분들께 도움이 되었으면 좋겠습니다.
내년엔 아마도 회사에 가게 되기 때문에, 대회 출제는 3년 후에나 다시 하게 될 것 같습니다. 그 때는 난이도 조절에 조금 더 신경을 쓰고 싶습니다. 같이 출제해 주신 서강대학교 학우님들, 검수를 도와주신 분들과 참가자 분들께 모두 감사드립니다.



























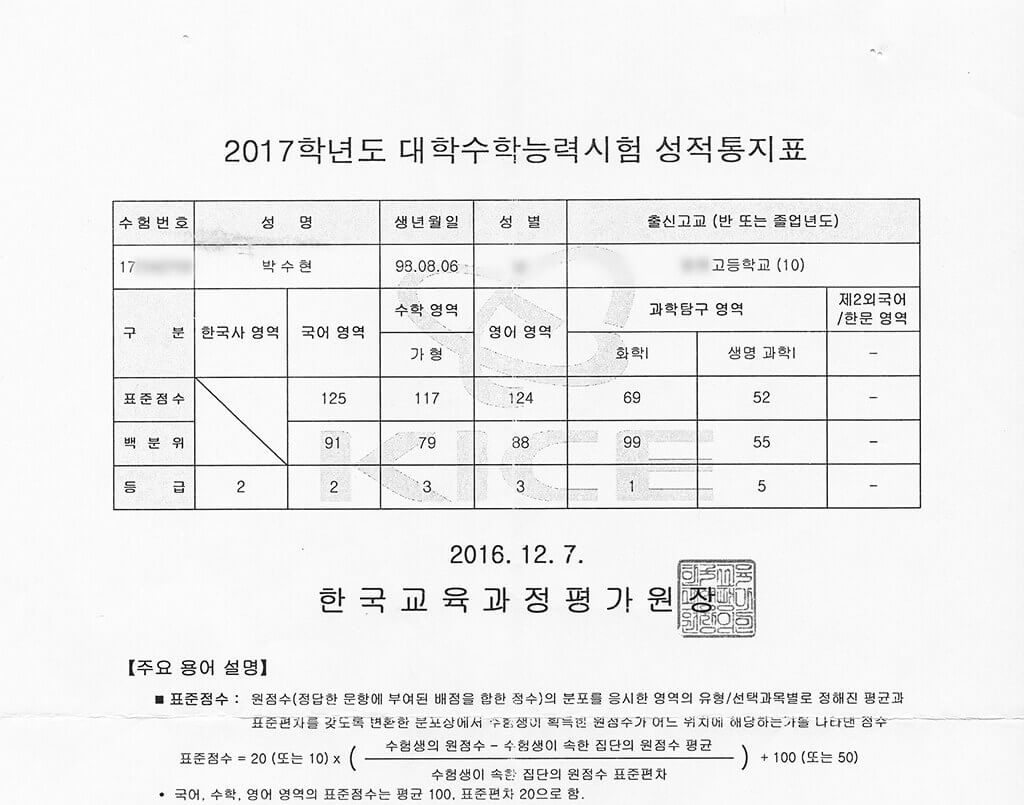


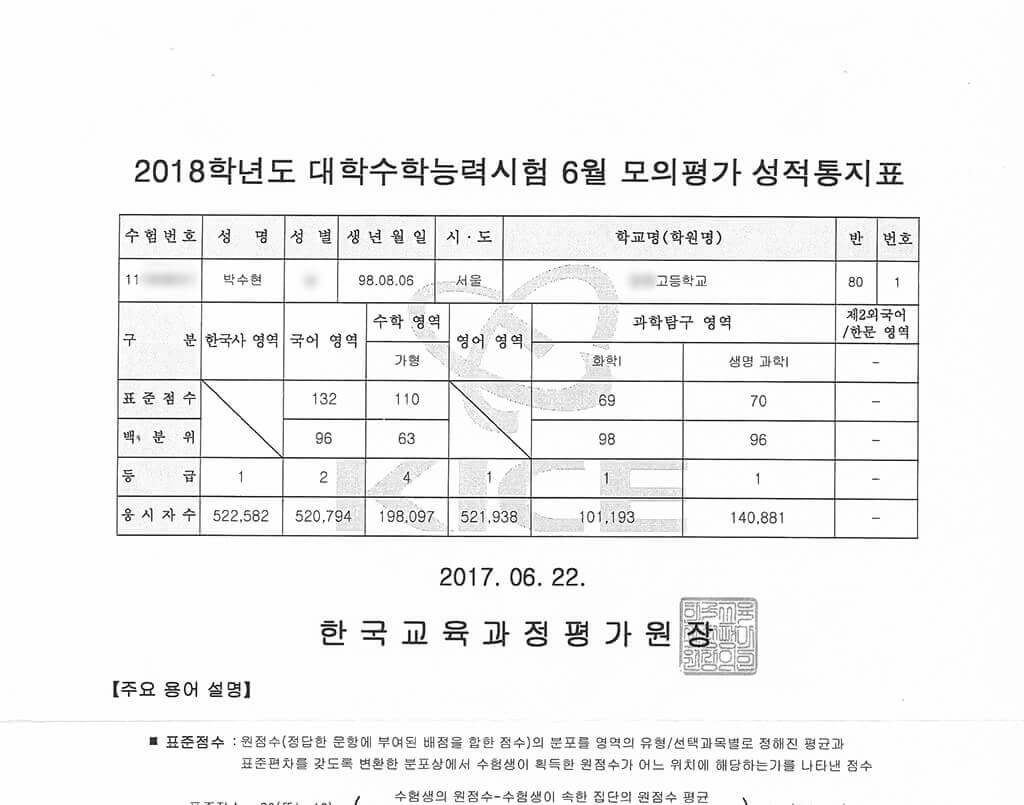

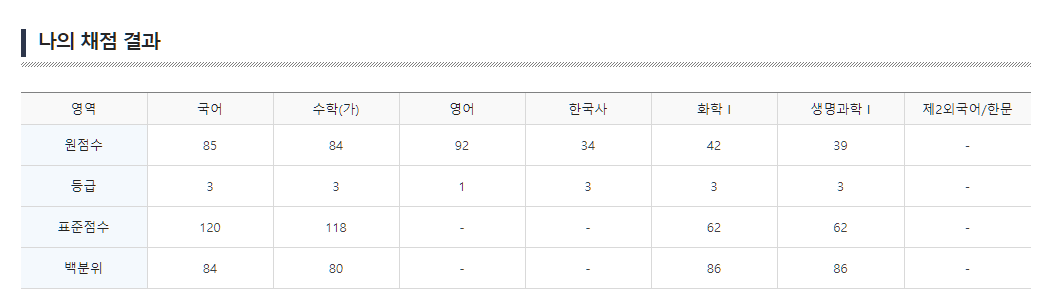


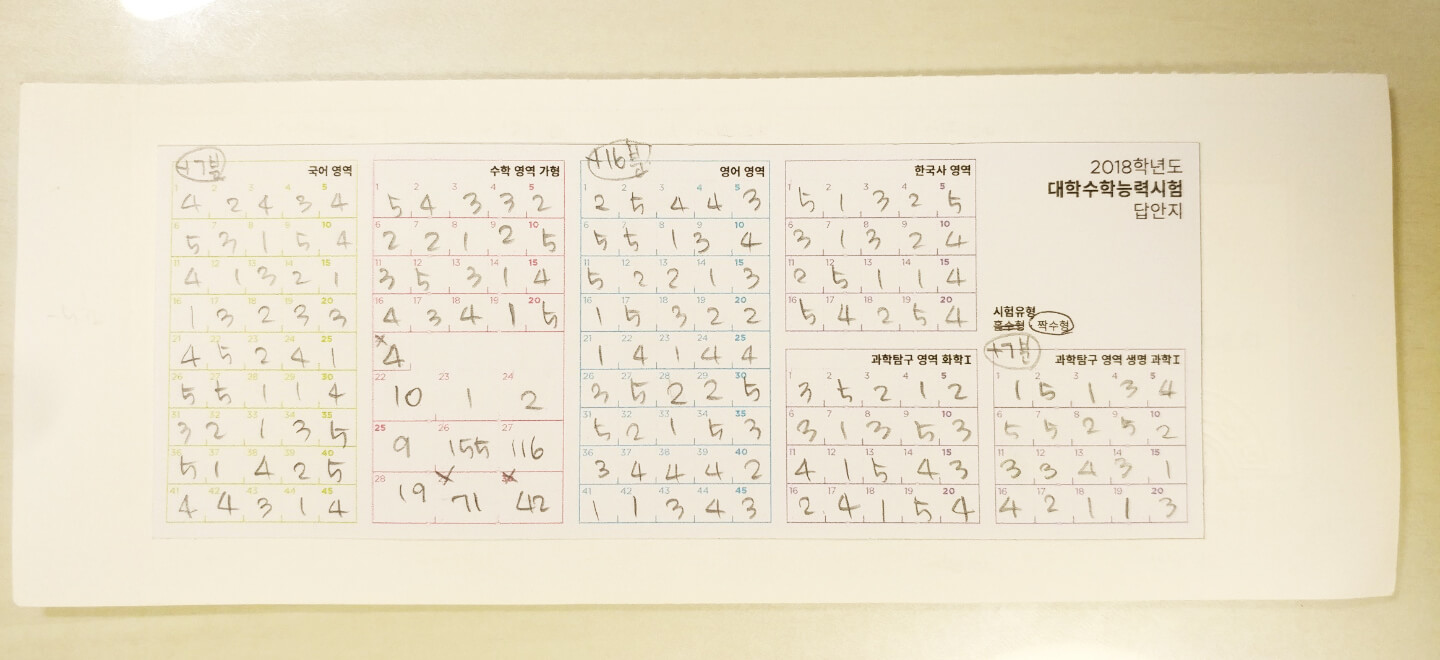
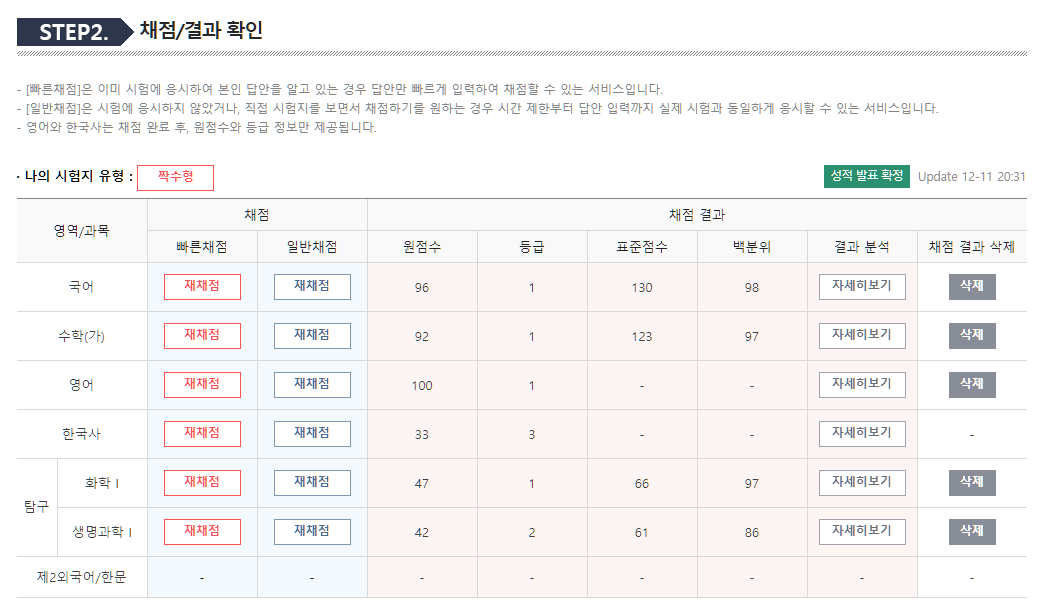
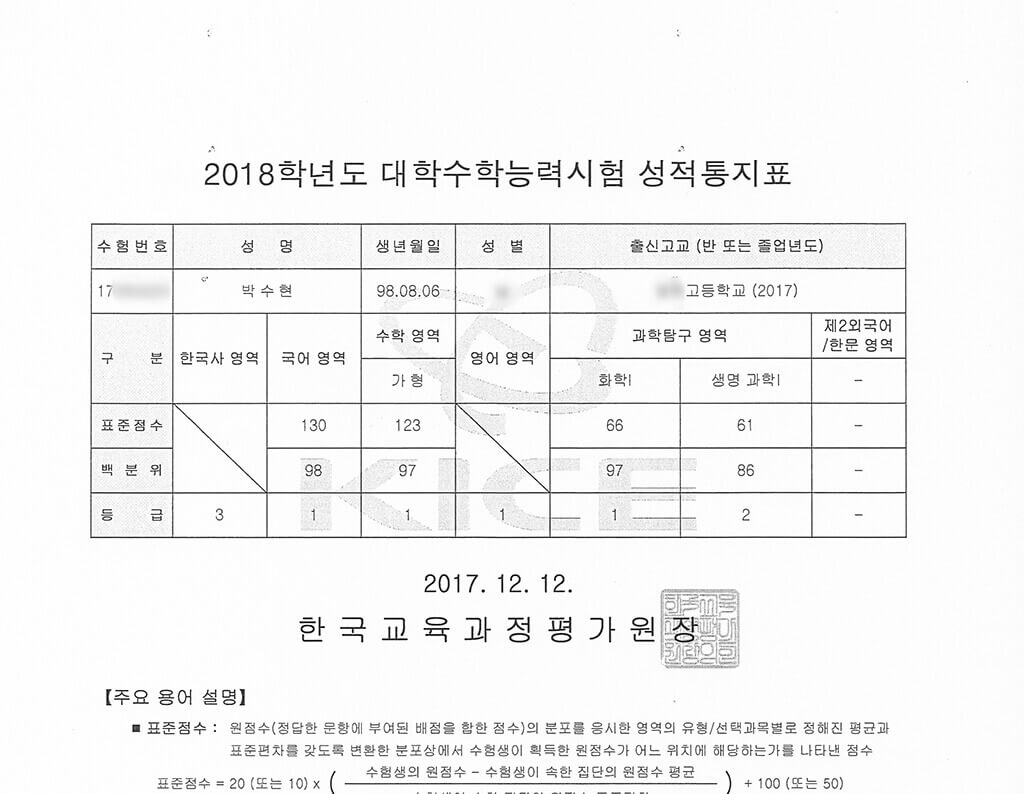 한국사를 제외하고 17수능에 비해 여덟 등급이 올랐습니다.
한국사를 제외하고 17수능에 비해 여덟 등급이 올랐습니다.