[mathjax]
인터넷에서 acm-icpc 2016 평양 리저널 문제를 찾았습니다. 북한 문제는 어떤 수준인지, 컴퓨터 과학 용어는 우리와 얼마나 많이 차이나는지 궁금해서 저화질의 사진을 보기 쉽게 글로 다시 정리해 보았습니다. 줄바꿈과 일부 기호는 임의로 수정했습니다.
총 12문제로 구성되어 있습니다. 개인적으로는 Mathforces 대회 같은 느낌의 문제들이라고 생각됩니다.
모든 문제는 ICPC Live Archive에서 풀어볼 수 있습니다. 시간제한이 다릅니다.
문제 1. 배렬전도수
설명
당신들은 모두 배렬의 전도수에 대하여 알것이다. 배렬 \(\left\{ a_1, a_2, \cdots, a_n \right\} \)의 전도수는 \(i < j\)이고 \(a_i > a_j\)인 \(\left(i, j \right)\)의 쌍의 개수로 정의한다.
한민이는 총명한데 지금 새로운 배렬의 전도수를 생각하고있다.
만일 \(i\) 와 \(j\) 의 짝홀성이 같으면서 \(a_i > a_j\)이면 그는 \(\left(i, j \right)\)를 전도된 쌍으로 생각한다. 한편 짝홀성이 다르면서 \(a_i < a_j\)이면 그는 이런 쌍\(\left(i, j \right)\)도 전도된 쌍으로 생각한다. 다른 말로 말한다면 첨수쌍 \(\left(i, j \right)\)는 \(i\) 와 \(j\) 의 짝홀성이 같을 때 \(a_i > a_j\)이거나 다를 때 \(a_i < a_j\)이면 전도된 쌍이다.
당신은 한민의 딱친구이고 배렬의 전도된 쌍의수를 계산할데 대한 부탁을 받았다. 당신은 풀수 있는가?
입력
입력파일의 첫행은 입력자료개수 \(T \left(1 \leq T \leq 5\right)\)로 되어있다.
매입력자료의 첫행은 한개의 옹근수 \(N \left(1 \leq N \leq 5000\right)\)을 포함하는데 그것은 배렬의 길이이다.
다음행에 \(N\) 개의 실수가 공백단위로 분리되어 들어온다.
출력
당신은 매 입력자료별로 한행에 전도수를 찍는다.
표준입력
1
5
1 4 3 2 5
표준출력
5
문제 2. \(B_N\)
설명
총명한 학생 리기웅은 물리를 아주 잘하지만 수학은 잘하지 못한다. 그의 동무 신영진은 반대로 수학을 잘하고 물리를 잘하지 못한다. 그래서 리동무는 신동무의 물리숙제를 도와주고 신동무는 리동무의 수학숙제를 도와준다.
오늘 리동무는 아주 힘든 수학문제를 받아가지고 와서 신동무에게 물어보았다. 그러나 신동무는 아주 바빠서 그는 당신에게 풀어줄것을 부탁하였다. 당신은 신동무의 딱친구이며 반드시 그것을 풀어야 한다. 문제는 다음과 같다.
배렬 \(\left\{ A_1, A_2, \cdots, A_n \right\} \)이 주어졌다. 새로운 배렬 \(\left\{ B_1, B_2, \cdots, B_n \right\} \)은 다음의 공식에 따라 정의된다.
\[ B_N = \left( \sum_{\substack{i_1+i_2+\cdots+i_k=N \\ 1\leq k \leq N}} A_{i_1}A_{i_2}\cdots A_{i_n} \right) \% 1000000007 \]
물론 \(1 \leq i_1, i_2, \cdots, i_k \leq n\) 이다. \(u \neq v\)에 대하여 \(i_u = i_v\)도 가능하다. 실제로 \(B_3 = A_1 \times A_1 \times A_1 + A_1 \times A_2 + A_2 \times A_1 + A_3\)이다. 당신은 반드시 주어진 \(N\)에 대하여 \(B_N\)을 계산해야 한다.
당신은 그들을 도와줄수 있는가?
입력
입력파일의 첫행은 입력자료개수 \(T\)로 되어있다.
매 자료의 첫행은 두개의 옹근수 \(n\) 과 \(N\)으로 되어있다. \(\left(1 \leq n \leq 100, 1 \leq N \leq 100\right)\)
다음행에는 \(n\) 개의 옹근수가 공백단위로 분리되어 들어온다.
출력
문제의 결과를 출력하시오.
표준입력
1
2 5
3 2
표준출력
495
문제 3. 행렬검사
설명
정교수는 제 41 차 국제대학생프로그람아시아평양지역경연 문제출제자이다. 그는 100개조의 2016 × 1946 행렬과 1946 × 2016행렬의 곱하기를 끝냈다. 물론 결과는 2016 × 2016행렬식이다. 계산하는데 거의 10일 걸렸다. 결과는 100개조이고 문제 C의 입출력자료로 될것이다.
계산이 끝난 후 정교수는 잠들었고 그의 아들이 결과에 손을 댔다. 그는 어느 한 수의 하나의 자리를 지우고 수자 1을 써넣었다.
다음날 정교수는 매우 성났다. 그러나 아들애는 겨우 2살이어서 모든것을 기억하지 못한다.
정교수는 그의 아들의 말을 들어보고 세부를 검사한다. 그래서 그는 아들이 매 조의 한수의 하나의 자리수를 변화시켰고 그 수자가 2, 0, 1, 6 중의 하나라는것을 알았다. 그리고 그는 아들이 변화시킨 위치가 행번호와 렬번호가 70 이하라는것을 알았다. 행렬의 왼쪽웃구석의 번호는 (1, 1) 이다. 첫 첨수는 행번호이고 다음번호는 렬번호이다.
그는 입출력을 오늘중으로 전송하여야 한다. 그래서 그는 결과를 검사할 결심을 하였다. 당신은 그의 우수한 학생이다. 정선생을 도우시오.
입력
입력파일은 꼭 100조의 입출력자료로 되어있다. 매 조는 다음과 같이 정의되었다.
첫행은 5개의 옹근수 \(a_1, a_2, a_3, a_4, a_5\)로 되어있다. 당신은 다음과 같이 행렬 \(A\)를 얻을수 있다.
\[A_{ij} = (a_1 \times i^4 + a_2 \times i^3 + a_3 \times j^2 + a_4 \times j + a_5) \% 1946002016\]
다음행은 5개의 옹근수 \(b_1, b_2, b_3, b_4, b_5\)로 되어있다. 당신은 다음과 같이 행렬 \(B\)를 얻을수 있다.
\[B_{ij} = (b_1\times i^4 + b_2\times i^3 + b_3\times j^2 + b_4\times j + b_5) \% 1946002016\]
다음 왼쪽웃구석의 70 × 70 옹근수 행렬이 있다. 당신은 이 행렬식을 검사하여야 한다.
당신은 두 행렬을 곱할 때 행렬을 반드시 2016011010에 관하여 나머지를 취한다.
출력
당신은 어느 입력조가 아들에 의해 변화되었는가를 출력해야 한다. 입력의 번호는 1부터 100까지 이다. 당신의 출력은 반드시 증가순서로 출력해야 하며 공백단위로 분리되어있어야 한다. 만일 모든 입력조들이 변화되지 않았다면 0을 출력하시오.
입력과 출력의 실례
입력과 출력이 너무 커서 우리는 당신들에게 입력과 출력의 실례를 보여줄수 없다. 당신은 입출력의 형식을 담보해야 한다.
문제 4. 사과나누기
설명
현일은 도덕있는 학생이다. 그는 항상 그의 학급동무들과 친구들을 자기자신처럼 대해준다. 하루는 그가 맛있고 큰 사과를 가져와 그의 친구들에게 나누어주려고 한다. 흥미있는것은 사과가 타원모양이라는것이다.
그는 항상 두가지 조작을 진행한다.
첫번째는 사과의 \(L\)부터 \(R\)각도사이의 남은 면적을 계산하는것이다.
둘째는 \(L\)부터 \(R\)각도사이의 모든 사과쪼각들을 주는것이다.
현일은 사과를 데카르트자리표계에 놓았으며 결과 사과는 타원 \(\frac{x^2}{a^2}+\frac{y^2}{b^2}=1\) 에 자리잡고있다.
현일의 형인 당신은 어린 동생의 계산능력을 시험해보려고 하는데 당신은 모든 질문들에 반드시 대답해야 한다.
할수 있는가? 있다.
아, 한가지 조건이 또 있는데⋯ \(prev\)는 마지막으로 출력된 수이며 실제 \(L\)과 \(R\)은 다음의 공식에 의해 계산된다.
\[L_{real} = \left( L_{given} + prev \right) \% 360, R_{real} =\left( R_{given} + prev \right) \% 360\]
만약 \( L_{real} > R_{real} \)이면 당신은 두값을 바꾸어야 한다. 당신은 조작을 \(L_{real}\)과 \(R_{real}\), 두값을 가지고 해야 한다. 처음에 \(prev = 0\)이다.
입력
입력파일의 첫행은 세옹근수를 포함한다. – \(a\) \(b\) \(n\) \(\left( 1 \leq a, b \leq 100, n \leq 300000 \right)\)
\(a\)와 \(b\)는 우에서 설명한 수이고 \(n\)은 조작회수이다.
다음의 \(n\)개 행은 세 수 “\(type\) \(L\) \(R\)”을 포함한다. (\(1 \leq type \leq 2\), \(L\)과 \(R\)은 임의의 실수이다.) \(0 \leq L + prev,0 \leq R + prev\) 라는것은 담보할수 있다.
출력
모든 조작1에 대해서 결과를 계산해야 한다. 소수점아래 5자리에서 반올림하여 출력하시오.
표준입력
10 10 3
1 10.00000 30.00000
2 40.00000 70.00000
1 10.00000 300.00000
표준출력
17.45329
226.89280
주해
문제가 쉬워 지도록 \(L\)과 \(R\)도 소수점아래 5자리로 주어진다. 그리고 \(prev\)는 마지막으로 출력된 첫번째 질문의 값이다. 실례로 \(prev = 17.45329\) 이지만 실제 대답은 \(17.453297519943295769236907684886\cdots\)이다.
문제 5. 쉬운 기하문제
설명
\(ABCD\)는 4면체이며 \(\overline{DA} = a\), \(\overline{DB} = b\), \(\overline{DC} = c\), \(\angle BDC = \alpha\), \(\angle ADC = \beta\), \(\angle ADB = \gamma\)로 주어진다. 당신은 \(ABCD\)의 내접원반경을 계산해야 한다.
입력
첫행은 입력자료개수 \(T (1 \leq T \leq 100000)\)로 되어있다.
매 입력자료는 6개의 수 \(a, b, c, \alpha, \beta, \gamma\) \((1 \leq a, b, c \leq 100, 0 < \alpha, \beta, \gamma < 360)\) 을 포함한다.
출력
내접원의 반경을 소수점아래 6자리에서 반올림하여 출력하시오.
표준입력
1
10 10 10 90 90 90
표준출력
2.113249
문제 6. 가장 좋은 경로찾기
설명
비트시는 바이트랜드의 수도이다. 비트시에는 현대적인 고속도로체계가 있으며 그 체계는 자주 갱신되는데 고속도로들이 체계에 추가된다. 체계는 교차점들을 연결하는 고속도로들로 이루어져있다.
운수회사 사장인 당신은 어느 한 교차점에서 다른 곳으로 콤퓨터들을 수송하려고 한다. 그런데 바이트랜드에서 휘발유값이 너무 비싸 당신은 한대의 화물자동차로만 나르려고 한다. 당신은 가능한껏 많은 콤퓨터들을 나르려고 하지만 모든 고속도로들은 \(W\)대이상의 콤퓨터들은 나를수 없다는 제한을 가지고있다.
당신은 나를수 있는 콤퓨터의 최대값을 계산해야 한다. 당신의 초기의 고속도로체계상에서 임의의 두 교차점사이로 이동할수 있다. 다시말하여 원래 체계는 연결되었다.
입력
첫행은 입력자료개수 \(T (1 \leq T \leq 3)\)로 되어있다.
매 입력자료는 교차점과 도로수를 의미하는 두 옹근수 \(N\)과 \(M\)으로 시작된다. \((3 \leq N \leq 70000, N-1 \leq M \leq 150000)\)
다음의 \(M\)개행은 \(a\)와 \(b\)사이에 도로가 있으며 제한은 \(c\)임을 의미하는 세개의 옹근수 \(a\) \(b\) \(c\)를 포함한다. \((1 \leq a, b \leq N, 1 \leq c \leq 10000)\)
다음 행은 질문의 개수를 의미하는 하나의 옹근수 \(Q (1 \leq Q \leq 105000)\)를 포함한다. 모든 질문은 다음의 두 종류중 하나이다.
- \(a\) \(b\) \(c\): \(a\)와 \(b\)사이에 도로를 련결하며 제한은 \(c\)이다.
- \(a\) \(b\): \(a\)로부터 \(b\)로 나를수 있는 콤퓨터의 최대개수를 계산하시오. \((1 \leq a, b \leq N, 1 \leq c \leq 10000)\)
두 교차점사이에는 둘 혹은 그 이상의 도로가 있을수 있다.
출력
둘째 종류의 매 질문에 대해 나올수 있는 콤퓨터의 최대대수를 출력하시오.
표준입력
1
5 6
1 2 2
1 3 3
2 4 7
2 5 1
3 4 6
3 5 5
4
2 2 5
1 4 5 8
2 2 5
2 3 4
표준출력
5
7
6
문제 7. 좋은 날들
설명
당신은 두개의 날자 \(\texttt{y/m/d}\)와 \(\texttt{yy/mm/dd}\)를 입력 받는데 하나는 첫번째 좋은 날이고 하나는 마지막 좋은 날이다. 그것들사이의 모든 날들도 역시 좋은 날이며 다른것들은 그렇지 않다. 당신은 좋은 날자수를 계산해야 한다.
입력
첫행은 입력자료개수 \(T (1 \leq T \leq 10000)\)로 되어있다.
매 입력자료는 6개의 옹근수 \(y\) \(m\) \(d\) \(yy\) \(mm\) \(dd\)로 되어있다. \((1 \leq y, yy \leq 5000)\)
출력
좋은 날자수를 출력하시오.
표준입력
1
2016 11 8 2016 11 11
표준출력
4
문제 8. 효성과 광성
설명
영어소문자로 이루어진 긴 문자렬 \(S\)가 있다. 두 소년 효성이와 광성이는 재미난 경기를 한다. 경기규칙은 다음과 같다.
초기에 심판원 학명이가 그들에게 비지 않은 \(S\)의 부분문자렬을 준다. (우리는 그것을 \(P\)로 표시하자.) 두명의 경기자는 교대로 뒤에 한개의 문자를 추가하여 새로 생긴 문자렬이 \(S\)의 부분문자렬이 되게 한다. 만일 그들이 문자를 추가하지 못하면 경기는 끝난다.
효성이는 마지막 문자렬이 가능한껏 짧게 하려고 하고 광성이는 문자렬이 가능한껏 길게 하려고 한다. 효성이는 첫 경기자이다. 만일 그들이 최량으로 경기를 한다면 매 문자렬에 대하여 추가되는 문자의 수를 추측할수 있다. (우리는 그것을 \(f(P)\)로 표시하자.)
부분문자렬 \(A\)는 만일 \(f(A) < f(B)\) 이거나 \(f(A) = f(B)\)이고 \(A\)가 \(B\)보다 사전순으로 앞에 놓이면 부분문자렬 \(B\)보다 작다고 정의한다.
주어진 옹근수 \(K\)에 대하여 문자렬 \(S\)의 \(K\)-번째로 작은 문자렬을 찾으시오. 찾아낼수 있는가?
입력
첫행은 한개의 문자렬로 되어있는데 그것의 길이는 500000 이하이다.
두번째행은 하나의 옹근수 \(K (1 \leq K \leq 1000000000)\)로 되어있다.
출력
결과 문자렬에 대하여 그것에 추가되는 문자의 수와 결과문자렬을 공백단위로 분리하여 출력하시오.
표준입력
aababb
8
표준출력
1 abab
문제 9. 국제망봉사
설명
지구상에는 수많은 망봉사기들이 있다. 모든 수 \(i\)에 대하여 \(i\)번째 망봉사기는 “반경” 이라고 불리우는 지수값 \(R_i\)를 가지고있으며 봉사기는 자기로부터 떨어진 거리가 \(R_i\)이하인 모든 점들까지 봉사할수 있다.
일부 점들은 많은 봉사기들로부터 봉사받을수 있다. 너의 과제는 최대로 많은 개수의 봉사기로부터 봉사받을수 있는 점을 찾는것이다.
지구는 6370의 반경을 가진 완전구로 보며 지구겉면의 구 점사이거리는 유클리드거리가 아니라 겉면상에서의 거리이다.
문제를 쉽게 하기 위해 망봉사기들의 반경을 2012 부터 2016 사이로 한다. (2012와 2016 포함)
입력
첫행은 입력자료개수 \(T (1 \leq T \leq 6)\)로 되어있다.
매 입력자료의 첫행은 봉사기의 대수 \(N (1 \leq N \leq 1000)\)을 포함한다.
다음 \(N\)개 행은 봉사기의 경도와 위도, 반경을 나타내는 세 옹근수를 포함한다. (0 ≤ 경도 < 360, -90 < 위도 < 90)
출력
문제의 답을 출력하시오.
표준입력
1
2
0 0 2012
0 1 2016
표준출력
2
문제 10. 보석통
설명
성영은 아무런 수학문제도 아주 빨리 풀수 있다. 그의 형 최광은 비싼 보석들을 보관할수 있는 빈 \(N\)개의 보석통들을 가지고있다.
하루는 최가 보석상점에서 \(N\)개의 보석을 가져왔다. 최는 모든 보석들을 한통에 한개씩 넣을것이다. 다시말하여 그는 매통에 오직 하나의 보석을 보관할것이다.
모든 보석들은 4개의 수를 가지고있는데 보관번호 \(p\), 통에 도착하는 시간 \(t\), 그리고 2가지 값 \(a\)와 \(b\)를 가진다. \((p, t, a, b)\)에대한 설명을 하자.
보석\((p, t, a, b)\)이 도착하면 최는 이미 도착한 보석들가운데서 가장 잘 결합되는 보석을 찾아내야 한다. 가장 잘 결합되는 보석\((p_1, t_1, a_1, b_1)\)은 다음의 조건을 만족시켜야 한다.
- 그것은 반드시 새 보석보다 먼저 도착하여야 한다. 다시말하여 \(t_1 < t\).
- 그것의 통번호는 \(p\)보다 작아야 한다. 다시말하여 \(p_1 < p\).
- 결합효과가 최대로 되어야 한다. 결합효과는 다음과 같이 정의한다. \(a_1 \times a + b_1 \times b\).
그리고 최는 그 통의 뚜껑에 보석들의 결합효과를 써넣으려고 한다. 그래서 최는 성영에게 매통의 뚜껑에 수를 계산하여 써놓을것을 부탁했다. 성영을 도와주자.
입력
첫행은 옹근수 \(N (1 \leq N \leq 100000)\) 을 포함하는데 이것은 보석통의 개수이다.
그리고 다음 \(N\)개의 행이 있다.
\(p\)번째행은 3개의 변수 \(t\) \(a\) \(b\)를 포함한다. – 그곳은 보석 \((p, t, a, b)\)를 의미한다. \((1 \leq t \leq 1000000000, 1 \leq a, b \leq 1000000)\)
어느 두개의 보석도 동시에 도착하지는 않는다.
출력
\(N\)개의 옹근수들을 출력하시오. \(p\)번째수는 \(p\)번째 뚜껑에 써넣을 수이다.
표준입력
3
1 1 1
2 2 2
3 3 3
표준출력
0
4
12
문제 11. K번째 그라프 절단
설명
지성은 그라프리론을 배우기 좋아한다. 처음 그는 최소생성나무에 대하여 배웠다. 다음 그는 최단경로에 대하여 배웠다. 그리고 그는 지금 그라프의 절단문제에 대하여 배우고있다.
무게붙은 방향그라프(그것은 연결이 아니어도 된다)와 원천과 목적지가 주어진다. 말할 필요는 없지만 원천과 목적지는 그라프의 한개 정점이다.
다음 당신은 그라프에서 원천지와 목적지사이에 아무런 경로도 없게 그라프에서 마디를 없애야 한다. 그때 제거한 마디들의 무게 합을 “절단” 이라고 부른다.
지성은 이미 일반그라프에서 최소절단이 원천지와 목적지사이의 최대흐름과 같다는것을 알고있다. 그리고 그는 지금 \(K\)째 최소절단에 대해서 알고싶어한다. 그는 \(K\)째 최소생성나무와 \(K\)째 최단경로를 구할수 있지만 \(K\)째 최소절단을 구할수 없다. 그를 도와주자.
입력
첫행은 5개의 옹근수 \(N\) \(M\) \(K\) \(S\) \(T\)를 포함한다.
\(N (1 \leq N \leq 100)\) – 그라프의 정점수를 의미한다.
\(M (1 \leq M \leq 1000)\) – 그라프의 마디수를 의미한다.
\(K (1 \leq K \leq 100)\)
\(S (0 \leq S < N)\) – 원천지의 정점번호.
\(T (0 \leq T < N)\) – 목적지의 정점번호. \((S \neq T)\)
다음 \(M\)개 행은 3개의 옹근수 \(a\) \(b\) \(c\)를 포함한다. – \(a\)와 \(b\)사이의 미디이며 그것의 무게는 \(c\)이다. \((0 \leq a, b < N, a \neq b)\)
문제를 쉽게 하기 위하여 매 \(i (0 \leq i < N, i \neq S, i \neq T)\)에 대하여 \(i\)와 \(T\)사이에 적어도 하나의 마디가 있다.
출력
문제에 대한 답을 출력하시오.
만일 \(K\)째 최소절단이 없다면 -1을 출력하시오.
표준입력
3 3 3 0 2
0 1 1
0 2 3
1 2 2
표준출력
6
문제 12. 긴옹근수 인수분해
설명
나는 대수를 아주 좋아하는데 특히 인수분해를 좋아한다. 긴옹근수 인수분해는 나에게 즐거움을 주지만 그것은 힘든 문제다.
나의 선생님은 새 인수분해 문제를 주었다. “옹근수 \(N\)이 주어졌을 때 큰 옹근수 \(N^4 + 64\)을 인수분해해야 한다.”
첫단계로 나는 \(N^4 + 64\)을 2개의 옹근수 \(a\) \(b\)의 적으로 표시하고싶다. 물론 \(1 < a, b < N^4 + 64\)이다.
나는 이것을 할수 있지만 바쁘다. 나를 도울수 있는가?
입력
첫행은 입력자료의 개수 \(T (1 \leq T \leq 10000)\)를 포함한다.
매 입력자료는 한개의 옹근수 \(N (1 \leq N \leq 10000)\)을 포함한다.
출력
\(N^4 + 64 = a \times b\)를 만족하는 \(a\)와 \(b\)를 출력하시오. 만일 여러가지 경우가 있다면 그중 하나를 출력하시오.
표준입력
1
1
표준출력
5 13



























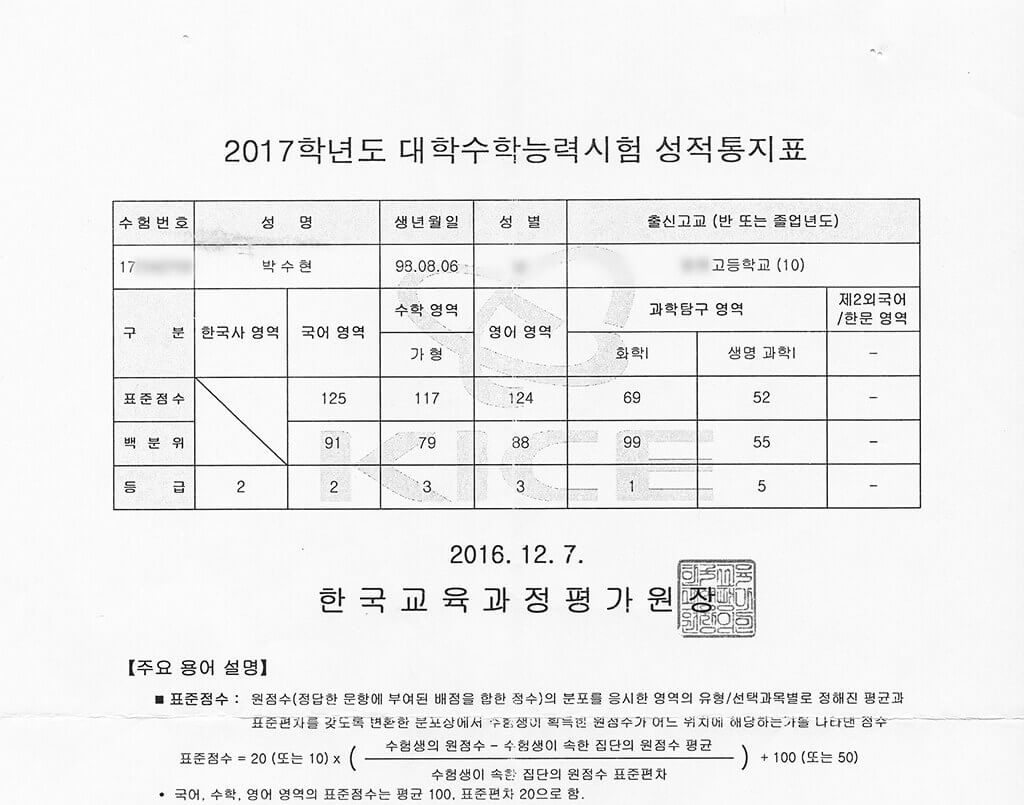


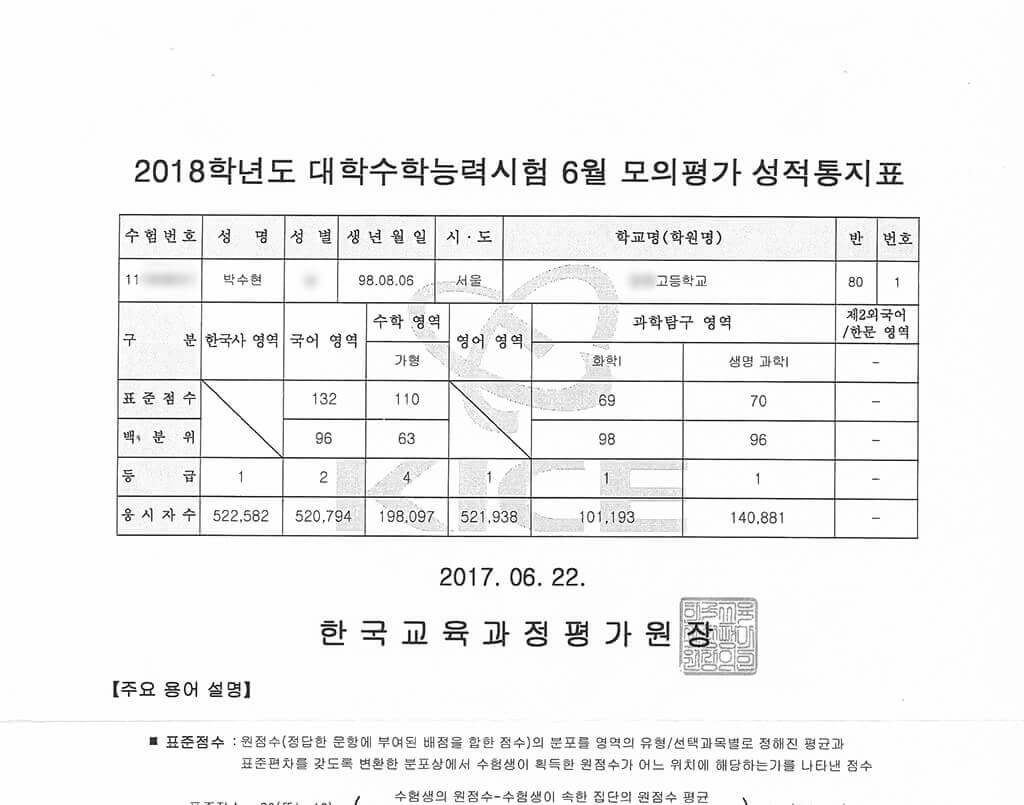

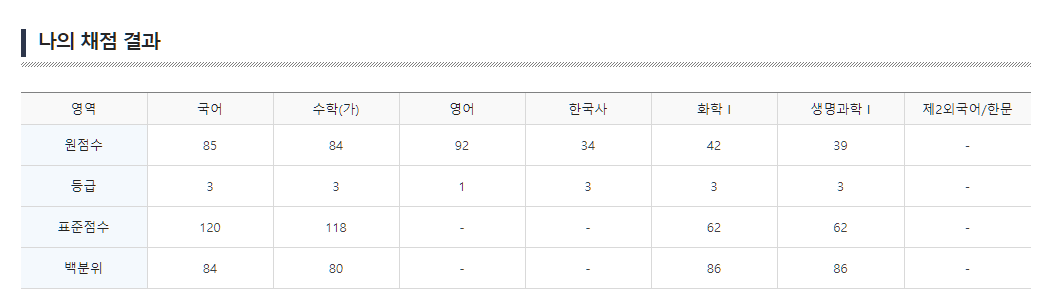


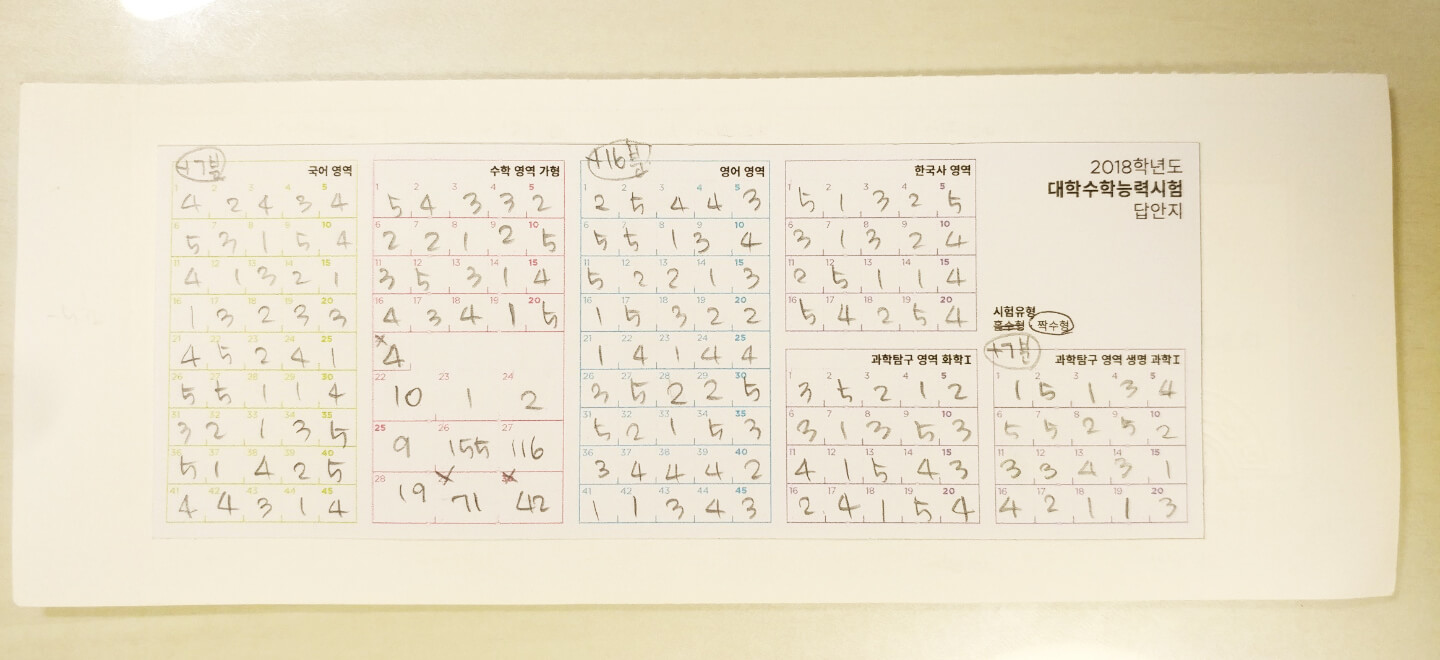
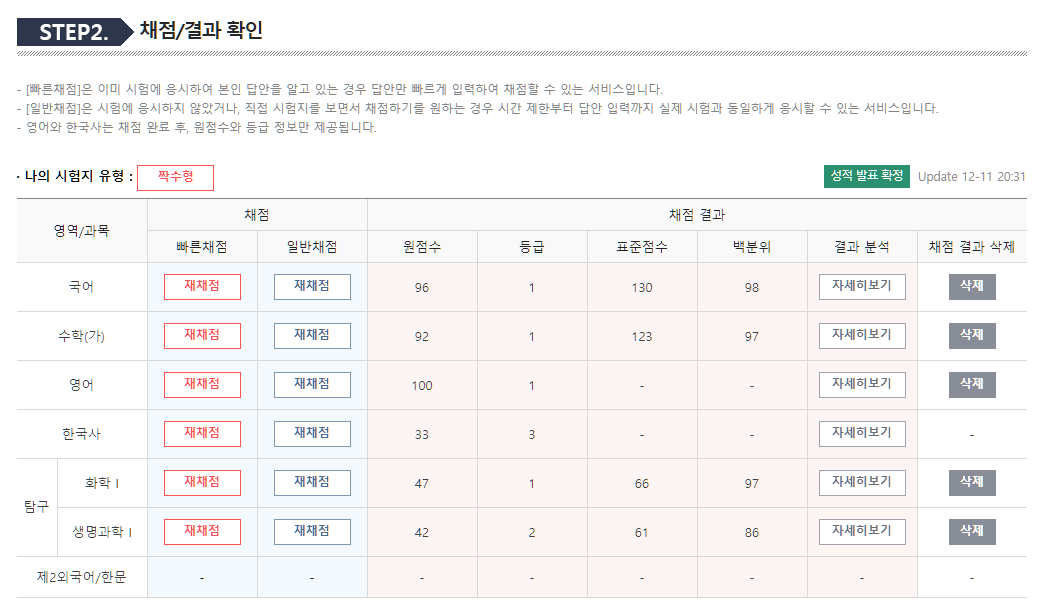
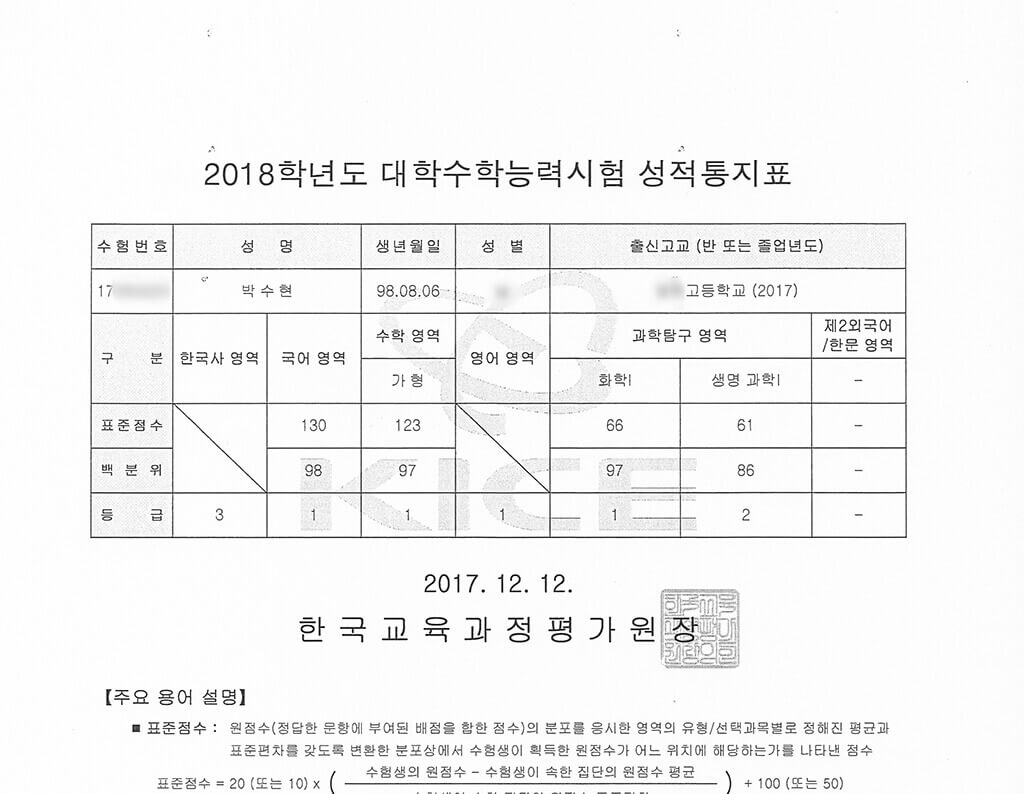 한국사를 제외하고 17수능에 비해 여덟 등급이 올랐습니다.
한국사를 제외하고 17수능에 비해 여덟 등급이 올랐습니다.